Q. 차원의 저주에 대해 설명해주세요. dimension reduction 기법으로 보통 어떤 것들이 있나요?
# 차원의 저주 - Curse of dimension
입력된 데이터의 수보다 데이터의 차원이 더 큰 경우 발생하는 문제를 차원의 저주라 합니다.
가령 입력한 데이터의 양은 100개 인데 각 데이터의 차원은 500인 상황입니다.
우리는 데이터(벡터)가 뿌려진 벡터 공간에서 분류 또는 예측하는 가장 적합한 함수를 찾는게 기계학습, 딥러닝 학습의 목표인데요.
입력한 데이터의 양은 적고, 데이터의 차원이 커지게 된다면
이때 벡터 공간의 차원이 무수히 커지고 데이터는 여기저기 흩뿌려져 있는 상황입니다.
이 흩어진 벡터들을 분류 예측하는 함수의 모형은 복잡해지게 됩니다.
즉, 모델의 복잡도가 증가하고 예측 성능이 낮아지게 됩니다.

선형대수로 표현하자면 0으로 가득한 벡터로 채워진 분산 행렬(sparse matrix)의 형태일 것입니다.
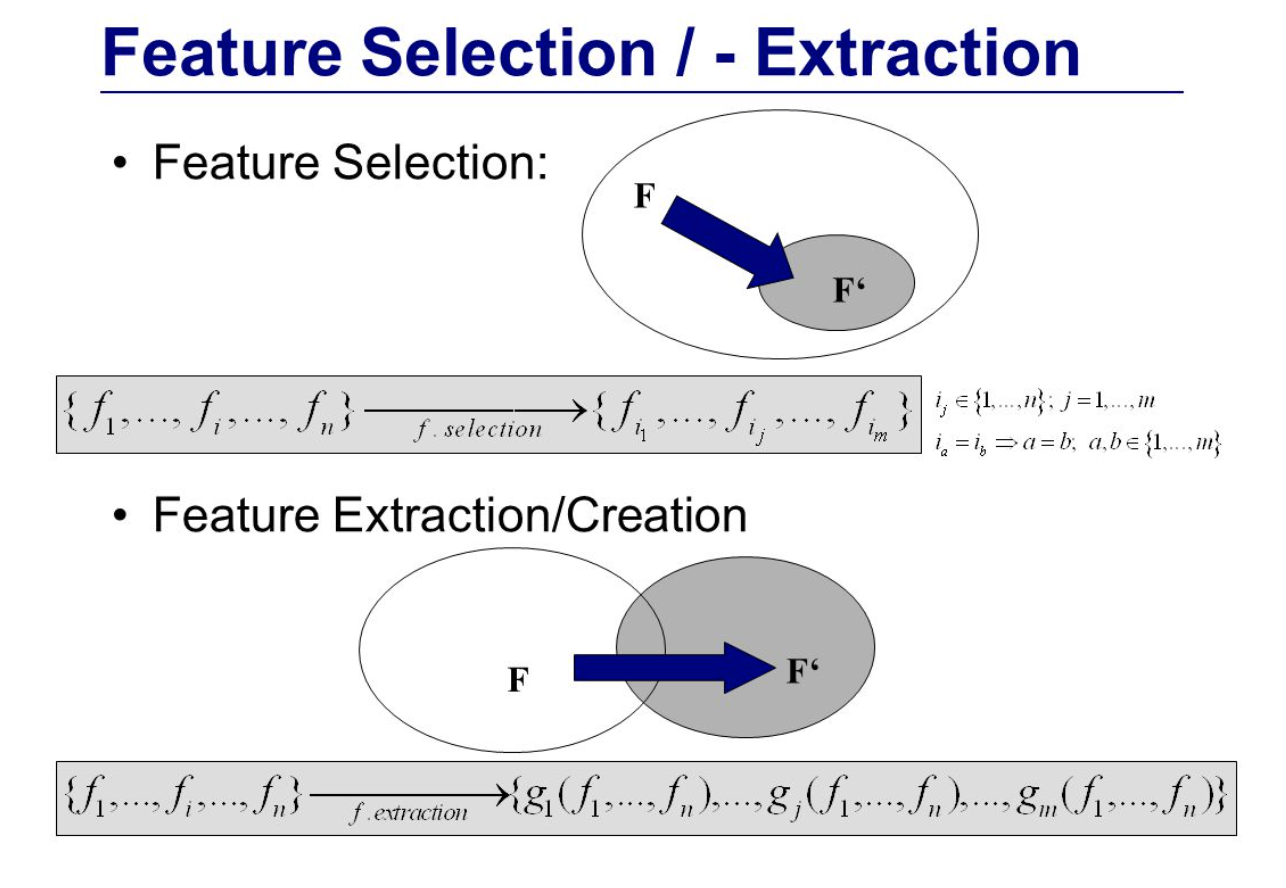
이를 위해서 사용하는 방법이 Feature selection (피쳐 선택), Feature Extraction(피쳐 추출) 입니다.
# 피쳐 선택과 피쳐 추출
피쳐 선택은 가령 500개의 차원중 N개의 차원을 골라 내는 것이고, 반면 피쳐 추출은 500개의 차원을 N차원으로 압축하는 겁니다.
피쳐 선택의 경우에는 다중공산성을 고려해 상관성이 높은 피쳐들을 소거해가는 방식으로 진행할 수 있고,
피쳐 추출의 경우는 PCA, SVD, MF 와 같은 차원 축소 기법들을 활용해 벡터의 차원을 줄여나갈 수 있습니다.
자세한 설명은 huidea.tistory.com/59
+) 꼬리 질문 - 만약 분석해야 할 데이터의 차원은 너무 크고 데이터 양은 너무 적다 어떻게 해결할건가.
데이터의 양 적음은 데이터의 유형마다 다르겠지만, 가능하다면 Data Augmentation
차원이 큰 것은 차원 축소 기법 활용,
# PCA는 차원 축소 기법이면서, 데이터 압축 기법이기도 하고, 노이즈 제거기법이기도 합니다. 왜 그런지 설명해주실 수 있나요?
주성분 분석의 기본적인 개념은 차원이 큰 벡터에서 선형 독립하는 고유 벡터만을 남겨두고 차원 축소를 하게 됩니다.
이때 상관성이 높은 독립 변수들을 N개의 선형 조합으로 만들며 변수의 개수를 요약, 압축해 내는 기법입니다.
그리고 이 압축된 각각의 독립 변수들은 선형 독립, 즉 직교하며 낮은 상관성을 보이게 됩니다.
가령 500차원의 벡터를 주성분 분석한다는 것은 각 차원의 분산을 최대로 갖는, 분포를 설명할 수 있는 대표축을 뽑는 과정이고,
주성분 분석결과 나오는 매트릭스에서 PC1 은 각 칼럼에 대한 정보 설명력이 PC5~6에 비해 높습니다.
이처럼 높은 주성분들만 선택하면서 정보 설명력이 낮은, 노이즈로 구성된 칼럼들은 배제하기 때문에
노이즈 제거 기법이라고 불리기도 합니다.

Q. LSA, LDA, SVD 등의 약자들이 어떤 뜻이고 서로 어떤 관계를 가지는지 설명할 수 있나요?
LDA 는 토픽모델링(Topic Modeling) 기법 중 하나인 잠재디리클레할당(Latent Dirichlet Allocation, LDA)와 이니셜이 같아서 헷갈리는데 SVD (행렬분해)를 자연어처리 토픽 모델링에 적용한게 잠재디리클레할당(Latent Dirichlet Allocation, LDA)고,
또 다른 LDA (Linear Discriminant Analysis)는 PCA 에서 확장된 차원 축소 기법입니다.
PCA 데이터의 차원을 줄이기 위해, 공분산 행렬에서 고유 벡터/고유값을 구하고
가장 분산이 큰 방향을 가진 고유벡터에 입력데이터를 선형변환하는 컨셉이라면,
LDA는
지도 학습(supervised - learning)에서 적용하는 차원 축소 기법이자,
입력 데이터의 클래스(정답) 를 최대한 분리할 수 있는 축을 찾는 기법입니다.
SVD는
SVD는 정사각행렬이 아닌 m*n 형태의 다양한 행렬을 분해하며, 이를 특이값 분해라 말합니다.
이때 분해되는 행렬은 두 개의 직교 행렬과 하나의 대각행렬이며, 두 직교행렬에 담긴 벡터가 특이벡터입니다.




댓글