오늘의 질문 !
- 텍스트 더미에서 주제를 추출해야 합니다. 어떤 방식으로 접근해 나가시겠나요?
- SVM은 왜 반대로 차원을 확장시키는 방식으로 동작할까요? 거기서 어떤 장점이 발생했나요?
- 다른 좋은 머신 러닝 대비, 오래된 기법인 나이브 베이즈(naive bayes)의 장점을 옹호해보세요.
Q. 텍스트 더미에서 주제를 추출해야 합니다. 어떤 방식으로 접근해 나가시겠나요?
토픽 모델링을 해야한다. 토픽 모델링에는 다양한 기법이 있지만 그중 가장 기초적인 기법 부터 하나씩 살펴보자면 ~
1. 잠재디리클레할당(Latent Dirichlet Allocation, LDA)
: LDA는 문서들은 토픽들의 혼합으로 구성되어져 있으며, 토픽들은 확률 분포에 기반하여 단어들을 생성한다고 가정
데이터가 주어지면, LDA는 문서가 생성되던 과정을 역추적 (wikidocs.net/30708)
1.1 기본 개념
ex.
문서1 : 저는 사과랑 바나나를 먹어요
문서2 : 우리는 귀여운 강아지가 좋아요
문서3 : 저의 깜찍하고 귀여운 강아지가 바나나를 먹어요
--> LDA는 각 문서의 토픽 분포와 각 토픽 내의 단어 분포를 추정!
<각 문서의 토픽 분포>
문서1 : 토픽 A 100%
문서2 : 토픽 B 100%
문서3 : 토픽 B 60%, 토픽 A 40%
<각 토픽의 단어 분포> --> 토픽의 개수 유사도 혼란도를 기반으로 사람이 지정
토픽A : 사과 20%, 바나나 40%, 먹어요 40%, 귀여운 0%, 강아지 0%, 깜찍하고 0%, 좋아요 0%
토픽B : 사과 0%, 바나나 0%, 먹어요 0%, 귀여운 33%, 강아지 33%, 깜찍하고 16%, 좋아요 16%
사람이 임의로 토픽의 수를 정하고, LDA 는 문서 내의 토픽 분포 확률과 토픽 내의 단어 분포 확률을 추정
( 이때 쓰는 분포가 디리클레 분포 )
1.2 학습 진행 방법
1) 토픽 4개라고 임의로 지정한다면,
2) 모든 문서에서 토큰을 끊고 토픽 네개로 랜덤하게 할당
" I am a boy " 첫문장이 이거였다면, "I" "am" "a" "boy" 각각을 1,2,3,4 토픽으로 처음에 임의로 할당해버림
3) 이렇게 전체 단어를 특정 토픽에 임의로 할당해놓고 이터레이션을 돌리며 학습을 진행하는 것
3.1 ) 학습 방식은 "am" "a" "boy" 가 제대로 할당 되었다는 가정을 하고 "I" 가 어디에 할당 되면 좋을 지 추정 !
- p(topic t | document d) : 문서 d의 단어들 중 토픽 t에 해당하는 단어들의 비율
- p(word w | topic t) : 단어 w를 갖고 있는 모든 문서들 중 토픽 t가 할당된 비율
 |
 |
 |
(1) 두 개의 문서 doc1과 doc2를. 여기서는 우리는 doc1의 세번째 단어 apple의 토픽을 결정하고자 함
(2) 우선 첫번째로 사용하는 기준은 문서 doc1의 단어들이 어떤 토픽에 해당하는지를 확인 ==> p(topic t | document d)
doc1의 모든 단어들은 토픽 A와 토픽 B에 50 대 50의 비율로 할당되어져 있으므로,
이 기준에 따르면 단어 apple은 토픽 A 또는 토픽 B 둘 중 어디에도 속할 가능성이 있음
(3) 두번째 기준은 단어 apple이 전체 문서에서 어떤 토픽에 할당되어져 있는지 확인 ==> p(word w | topic t)
이 기준에 따르면 단어 apple은 토픽 B에 할당될 가능성이 높음
==> 이러한 두 가지 기준을 참고하여 LDA는 doc1의 apple을 어떤 토픽에 할당할지 결정!!!
1.3 특징 !!!! (중요)
1) 잠재 디리클레 할당과, 잠재 의미 분석의 차이 (맨날 헷갈림)
잠재 디리클레 할당은 디리클레 확률로 문서중 토픽비율, 토픽중 단어 비율로 계산
잠재 의미 분석은 DTM (document term matrix) 에 SVD 로 차원축소 한후 근접단어 토픽 묶기
2) 잠재 디리클레 할당은 단어의 순서와 상관이 없다.
단지 특정 토픽에 존재할 확률과 문서에 특정 토픽이 존재할 확률을 결합확률로 추정하기 때문에
3) 디리클레 분포 추론 과정에서 깁스 샘플링을 이용하게 된다. (형이 거기서 왜나와?)
techblog-history-younghunjo1.tistory.com/87
[ML] Topic Modeling(토픽 모델)인 LDA(Latent Dirichlet Allocation)
※해당 게시물에 사용된 일부 자료는 순천향대학교 빅데이터공학과 정영섭 교수님의 머신러닝 전공수업 자료에 기반하였음을 알려드립니다. 이번 포스팅에서는 Clustering의 방법 중 하나이며 비
techblog-history-younghunjo1.tistory.com
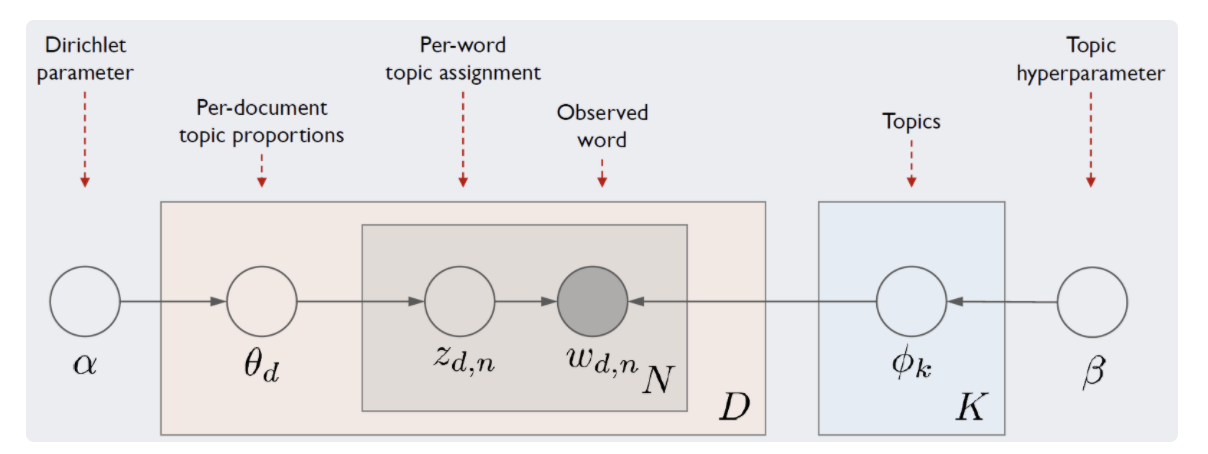
==> 수식을 뜯어보면 결국
1) 우리는 사후확률(posterior) p(z,ϕ,θ|w)를 최대로 만드는 z,ϕ,θ를 찾아야 함.
2) 사후확률을 구하려면 결국 분모인 p(w)를 구해야함
( 사후확률은 베이즈 정리에서 evidence 부분 즉, 잠재변수 z,ϕ,θ의 모든 경우의 수를 고려한 각 단어(w)의 등장 확률 )
3) 하지만 잠재변수 z,ϕ,θ를 모두 관찰하는 게 불가능 따라서 ==> 깁스 샘플링 사용.
자세한 내용은
ratsgo.github.io/from%20frequency%20to%20semantics/2017/06/01/LDA/
Topic Modeling, LDA · ratsgo's blog
이번 글에서는 말뭉치로부터 토픽을 추출하는 토픽모델링(Topic Modeling) 기법 가운데 하나인 잠재디리클레할당(Latent Dirichlet Allocation, LDA)에 대해 살펴보도록 하겠습니다. 이번 글 역시 고려대 강��
ratsgo.github.io
참고한 내용 출처 :
www.youtube.com/watch?v=noWKlkdcY6Awikidocs.net/30708




댓글