오늘은 Variational autoencoder를 Recommendation 영역에 활용한 RecVAE를 살펴보겠다.
RecVAE를 이해하려면 VAE에 대한 이해가 필요한 한데 해당 알고리즘의 설명은 아래의 링크 !
https://huidea.tistory.com/296
[Deep Learning] VAE (Variational Auto Encoder) 개념 정리
https://www.youtube.com/watch?v=GbCAwVVKaHY&t=546s 위 강의 링크 내용을 정리해서 요약한 내용입니다. 추가 참고 link : https://hugrypiggykim.com/2018/09/07/variational-autoencoder%EC%99%80-elboevidence..
huidea.tistory.com
1. 논문의 핵심 concept
추천 알고리즘 collaborative filtering에 Variational Autoencoder를 사용
이전, multi-vae (multinomial likelihood 사용) 에서 더 나은 성능을 구현하기 위해 몇가지 모델 구조 변형
- 새로운 prior distribution --> p(z) 가 아니라 p(z| φold,x)
- β - vae 논문에서 활용한 β hyperparameter 적용
- 학습과정에서 alternating update 적용
기존 autoencoder base 추천 알고리즘 Multi VAE와 RaCT보다 우수한 성능을 보임
+) multi vae - user-item interaction matrix를 압축 후 복원


- 원래 VAE loss function 에서 β가 추가됨
2. Backgroud & Related work
# VAE
Vae의 loss function : reconstruction error, regularization error



두번째 항도 0보다 큰 수이기 때문에 앞에 $Eq_{\phi}(z|x)$ 곱해져도 loss 계산에 큰 변동이 없음
# β - vae
- KLdivergence 앞에 베타 곱 추가, 정규화 계수의 역할

# D-vae (Denosing VAE)
+) DAE

DAE는 입력데이터에 일부러 노이즈한 input을 만들기위해 random noise나 dropout을 추가하여 학습한다.
이 input(noisy input)을 잘 복원할 수 있는 robust한 모델이 학습되어 전체적인 성능향상을 한다는 것이 DAE의 핵심 개념이다.
DAE concept + variational autoencoder
- 기존 variational autoencoder 식에서 Ep(x ̃ |x) noise 항을 곱함



# C DAE (collaborative Denoising Autoencoder)

$y_{u}$ : 한명의 유저u를 기준으로 모든 item에 대한 평점을 나타내는 벡터
$\tilde{y}_{u}$ : $y_{u}$ 에 DAE 처럼 노이즈 적용 (라는 확률에 의해 0으로 drop-out된 벡터)
$\hat{y}_{u}$ : 모델이 예측한 $y_{u}$ 값
그리고 개별유저에 대해서 라는 학습파라미터를 학습. (그림에서 User Node)
이는 유저에 따른 특징을 가 학습하고 Top N 추천에 사용

### Multi VAE 위의 모든 컨셉들이 합쳐진 알고리즘
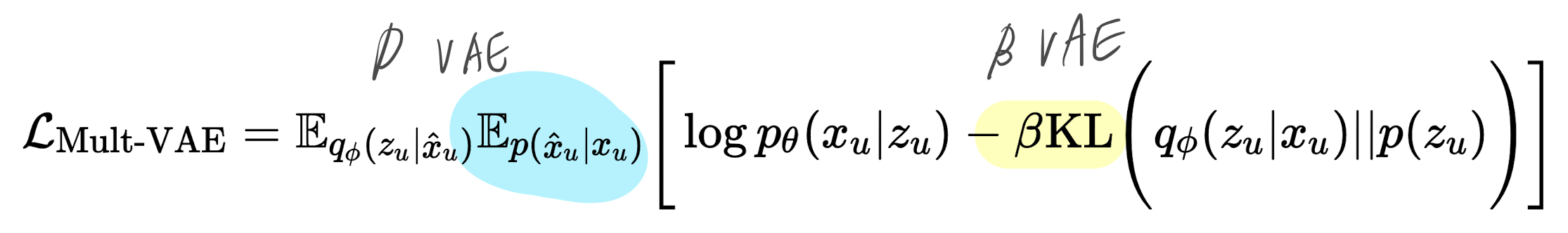
- u는 CDAE처럼 각 유저들
- DAE는 x의 noise $\tilde{x}_{u}$ 를 활용한 반면, mult vae에서는 $\hat{x}_{u}$ x의 타겟값을 활용
- 정답에 가까운 임베딩을 할 수 있도록 하는 것
- 일반 VAE와 가장 큰 차이점은 decoder 부분의 pθ(x|z) 가 베르누이가 아닌 다항분포를 따른다는 것
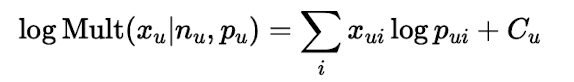
3. RecVAE
# RecVAE 의 구조 (VAE와 비교하여)

- 기존의 VAE는 encoder 의 output과 표준 정규분포 간의 KLdivergence를 구해서 regularization
RecVAE 는 encoder 의 output과 이전 epoch의 파라미터를 저장한 encoder(as a prior) 간의 KLdivergence
p(z) 표준 정규분포 대신 p(z| φold, x)
자세한 수식은 loss function에서..
- Encoder의 역할은 각 유저들의 각 아이템에 대한 피드백을 user embedding으로 변환해주는 역할
decoder의 역할은 원래의 user embedding 에서 유저-아이템 피드백으로 복원하는 역할
# RecVAE의 loss function (multi vae 와 비교해서...

" VAE에서의 p(Zu) 가 p(z| φold,x)로 바뀜 "
(( VAE, multi VAE )) KL 항은 Regularization error
encoder의 아웃풋 과 우리가 가정한 Z distribution p(z) 값이 유사하도록 하는 error
p(Z) 는 에서 표준정규분포를 의미했음
(( RecVAE )) p(z) 표준 정규분포 대신 p(z| φold,x)

p(z| φold,x) = 표준 정규분포 + 이전 epoch에서의 encoder(as prior)의 output
φold는 이전 epoch의 parameter를 의미함
- latent code z에 대해서는 표준정규분포를 사용
- KL divergence 사이에 별도의 regularization인 qφ(z∣x)와 qφold (z∣x)를 추가
- 수식의 첫번째 항은 overfitting을 방지 해주는 역할, 두번째 항은 optimization 중 large step을 조정하는 보조적인 loss function
4. Experimental Evaluation
- 활용 데이터 셋 : MovieLens20M, Netflix prize dataset, Milloin songs Dataset
- 활용 알고리즘 :
1) collaborative Filtering (WMF, SLIMl, EASE)
2) WARP, Lambdanet
3) Auto Encoder (RaCT, CDAE, Mult-DAE, Mult-VAE, RecVAE)

3가지 데이터셋에 대한 Top-N 추천 결과 이전의 모든 Auto encoder 계열 모델 성능은 능가함
그럼에도 불구하고 ML20m을 제외한 나머지 데이터 셋에서는 EASE와 RaCT가 우수한 성능을 보임
VAE 설명 (글설명위주 ) : https://deepinsight.tistory.com/127
VAE loss function 설명 (수식위주) : https://hugrypiggykim.com/2018/09/07/variational-autoencoder%EC%99%80-elboevidence-lower-bound/
변분추론 설명 : https://ratsgo.github.io/generative%20model/2017/12/19/vi/



댓글