논문 link : https://arxiv.org/pdf/1703.04247.pdf
오늘은 추천 알고리즘 중 click through rate (상품클릭률) task를 다루는 알고리즘 중 하나인
DeepFM(Deep Factorization Machine)을 살펴보겠다 !
해당 논문은 딥러닝 네트워크와 기존 CTR 분야에서 인정받던 머신러닝 알고리즘 FM을 합친 알고리즘이다
논문 한 줄 요약 :
상품, 광고, 고객 데이터 embedding 시킨 뒤에 concat 한 뒤
전체 벡터 값을 각각 Factorization machine 모델, Neural Network 모델에 태우고
각각 결과값 sigmoid로 계산해서
고객이 해당 상품광고 클릭할지 안할지(CTR) 판단하는 이진 분류 모델
1. Introduction (recommendation vs CTR )

- 위의 모델들은 추천 알고리즘에 초점
- 유저가 점수/ 클릭 여부에 대해서만 학습을 해서 괜찮은 성능을 보임
* 위의 두 추천 모델들의 한계점
- 유저에 대한 메타정보 (연령, 성별), 콘텐츠의 메타정보 (장르, 내용, 배우) 가 활용되지 않음
- BERT4REC - 추천할 수 있는 아이템이 이미 소비된 아이템만 가능
item 이 새로이 추가되면 아예 추천 할 수가 없음 (특정 확률로 최신 아이템을 랜덤하게 뿌리는 방식으로 실제는 쓰임) - 오토인코더도 마찬가지로 처음 벡터에 새로운 아이템에 대한 명시가 없으면, 추천을 할수가 없음
* CTR prediction
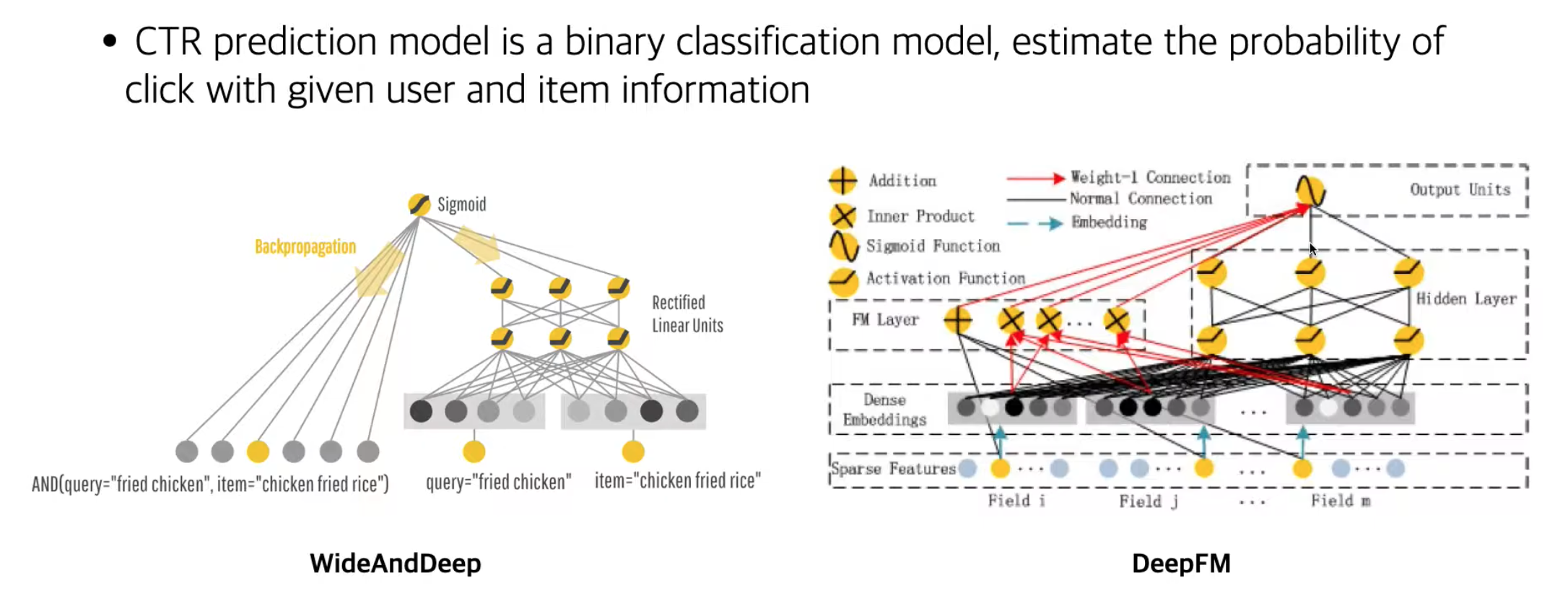
- 아이템을 추천해주는 것보다는 binary classification 문제 (이 광고를 해당 유저가 클릭을 할지 안할지)
- 유저의 메타정보, 아이템의 메타정보를 추가할 수 있음 (피쳐에 대한 제한이 없음) - sparse feature

- 좌측은 영화 추천, 우측은 CTR 광고 추천이라고 한다면
- 추천 모델 output : 각 유저 당 전체 item probability (학습 - 원본 matrix 와의 RMSE)
- CTR output : 선택 여부에 대한 하나의 output (학습 - binary cross entropy)
- CTR 은 메타정보를 활용하기 때문에 cold start problem (초기 아이템 정보가 없을때 생기는 문제)도 해결될 수 있음
광고가 노출 되기 전에 계산이 반드시 필요하기 때문에, 애당초 광고 영역에서는 과거 기록이 없는 상황에서 예측율을 높여야함
2. Related work (Deep FM 이해 하기 위해서 알아야 할 개념들 !)
2.1) FM & FFM

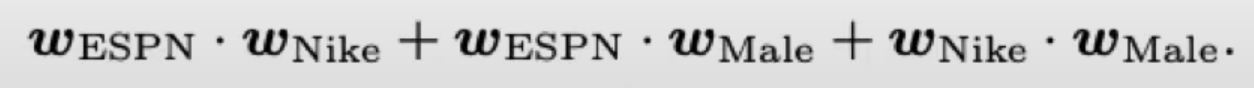
linear model 임의의 두 피쳐의 interaction을 구한 뒤 함께 연산
위의 예시로 들자면
- 기존 입력 모델의 feature : publisher - E, Advertser - N, Gender - M
- FM 모델의 feature : publisher - E, Advertser - N, Gender - M,
(publisher - E & Advertser - N), (Advertser - N & Gender - M), (publisher - E & Gender - M)
이렇게 각 피쳐들간의 조합도 피쳐로 활용을 해서 linear model input
FFM은 FM에서 하나의 과정을 더 추가 - weight도 어떤 피쳐와 연산을 하는지에 따라 차별화

즉 FM 에서 ( Espn & Nike ), (ESPN & male) 를 linear 모델에 넣으면
(Wespn * Wnike ) * Xespn * Xnike + (Wespn * Wmale) * Xespn * Xmale 였지만
FFM에서는 함께 interaction 하는 피쳐가 뭔지에 따라서 weight 를 차별화 한다.
(Wespn-a * Wnike-p ) * Xespn * Xnike + (Wespn-g * Wmale-p) * Xespn * Xmale
2.2) wide & deep learning
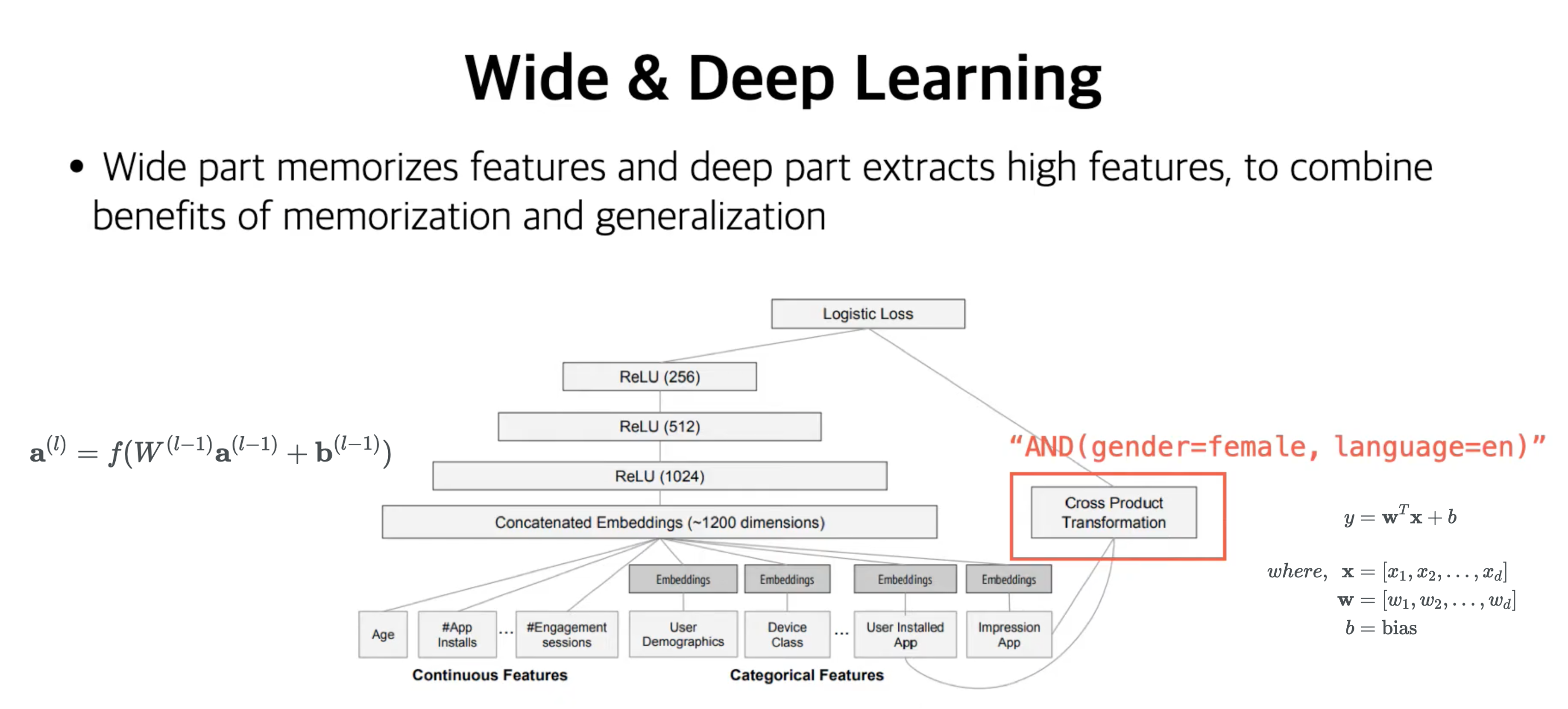
[ deep part ]
a. 연속형, 범주형 변수 넣고
b. 범주형은 sparse 하기 때문에 따로 embedding 시켜준 뒤에
c. concat 해서 FCNN 태우기
[ wide part ]
우측 오렌지 박스에서 FM과 비슷한 연산 : Cross product Transformation (여기에는 weight matrix는 없음)
+) 아래에 연산방법 조금 풀어서 설명하겠음
[ final - logistic loss ] : 이후 각각의 output을 합한뒤 sigmoid 통과

3. Deep FM
Embedding - m개의 feature를 k차원으로 임베딩
FM, DNN - k차원으로 임베딩된 m개의 feature들을 각각 FM, DNN에 input
sigmoid - FM 결과값과 DNN 결과값을 합한 뒤 sigmoid layer 통과
--> 낮은 수준의 상호작용은 FM으로 잡고, 고차원의 상호작용은 DNN 으로 잡는다.
low order feature interaction - FM, high order feature interaction - DNN
* 사실 아키텍쳐는 wide & deep 과 거의 유사한데,
wide part의 Cross product Transformation 대신 FM으로 바뀐것
* 여기서는 우리가 일반적으로 알고있는 feature가 field라고 표현됨
3.1) Embedding stage

sparse 한 원핫 인코딩된 데이터, 연속형 데이터 --> 각각 k차원으로 임베딩
ex. 5개의 범주형 데이터, 1개의 연속형 데이터
유저 메타 데이터 : 연령 범주 10개, 성별 범주 2개, 국가 범주 60개
광고 메타 데이터 : 상품군 범주 100개, 상품 브랜드 범주 2000개, 상품 금액
--> hidden layer로 전부 K차원으로 임베딩
--> 임베딩된 K차원의 벡터를 FM 과 DNN에 각각 input
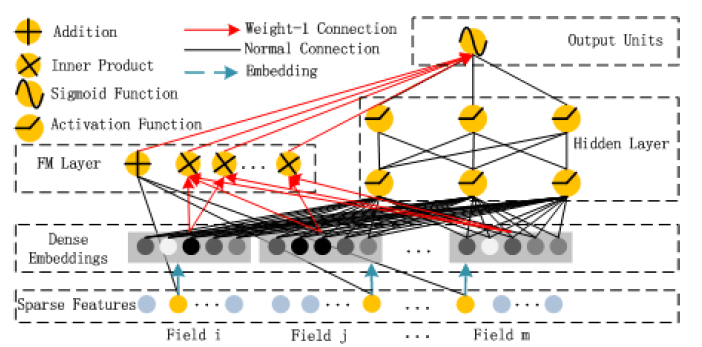
3.2) FM, DNN - k차원으로 임베딩된 m개의 feature들을 각각 FM, DNN에 input
3.2.1) FM

앞에서 말한 FM 개념 그대로 적용 - 임베딩 matrix 끼리 내적
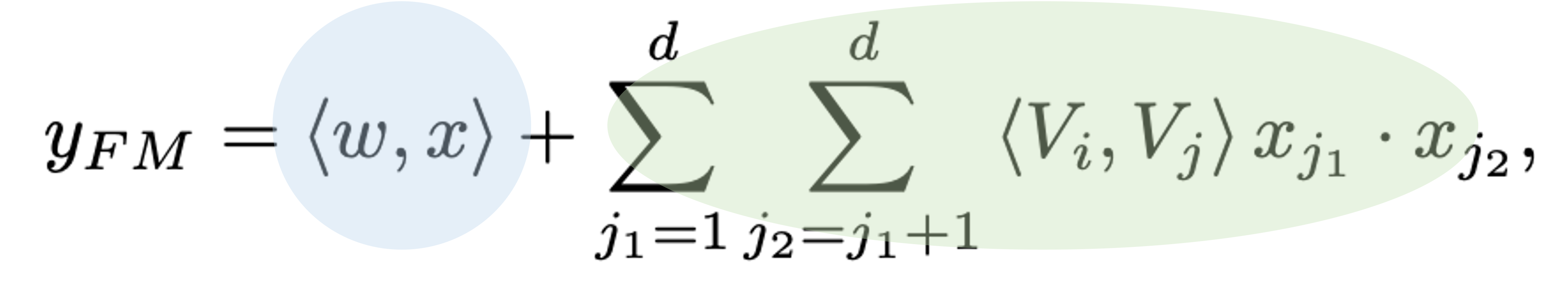
order1 (addition) - linear interactions (해당 피쳐의 중요도)
order2 (Inner product) - FM models pair wise interaction (다른 피쳐와의 interaction)
--> output : YFM
2.2) DNN

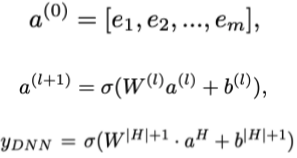
e1, e2, ... ,em : 임베딩 레이어 통과한 각 피쳐의 임베딩 벡터값 (필드 즉 피쳐가 m개니까)
a**(0) = m개의 임베딩 벡터 concat
이후 FCNN(DNN) 구조 통과한뒤 마지막에 sigmod 함수 output이 최종 결과값
--> output : YDNN
3) sigmoid - FM 결과값과 DNN 결과값을 합한 뒤 sigmoid layer 통과
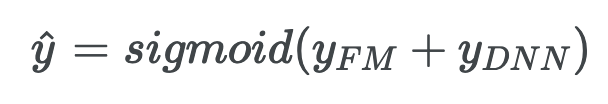
+) Cross product Transformation (참고 link : https://leehyejin91.github.io/post-wide_n_deep/ )
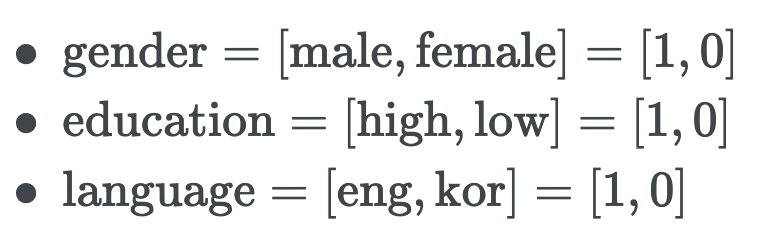

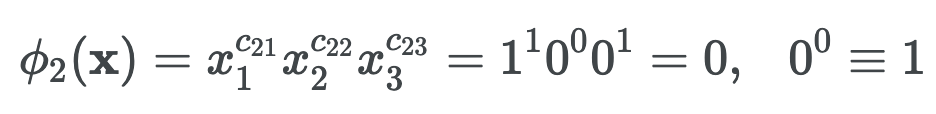
파이2는 gender와 language의 조합을 나타내고,
x의 지수인 C2i 는 i번째 피쳐를 파이2의 transformation에서 사용하는지 여부를 0,1로 나타내는 거다.
x는 각 피쳐별 원핫인코딩 된 값을 가져온다.
x는 남성, 고학력, 영어 이므로 --> x1 = 1, x2 =0, x3 = 0 이고
파이2는 gender와 language의 조합을 나타내므로, 가운데 education(x2) 에 대한 지수는 0이다.
gender(x1)와 language(x3)의 지수는 1이다.
결과적으로 x(남성, 고학력, 영어) 의 transformation 값은 0이다. 이런식으로 각각의 피쳐 조합에 대한 연산을 진행한다.
참고 link :
https://www.youtube.com/watch?v=zxXRGhSQ1f4
https://leehyejin91.github.io/post-deepfm/



댓글