추천 알고리즘에서 bert를 적용한 논문 bert4rec 을 살펴보겠다.
https://arxiv.org/abs/1904.06690
BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
Modeling users' dynamic and evolving preferences from their historical behaviors is challenging and crucial for recommendation systems. Previous methods employ sequential neural networks (e.g., Recurrent Neural Network) to encode users' historical interact
arxiv.org
[ index ]
0. 논문 핵심 내용
1. Introduction
2. Related Works
3. BERT4rec
4. Experiments
0. 논문 핵심 내용
" 논문 한 줄 정리 : BERT의 masked token prediction에서 단어token을 상품으로 바꾼 알고리즘 "
# BERT의 강점 : 양방향 Langauge modeling
| Auto regressive model (GPT, ELMO) | Auto encoding model (BERT) |
| 단방향 학습 모델 - next token prediction | 양방향 학습 모델 - masked token prediction |
| I ____ .... I went to the library to ____ I went to the library to read ____ I went to the library to read some ____ |
I went to the library to read some books ------------> <---------- |
# NLP BERT 를 추천에 적용
| NLP BERT | BERT4REC |
| 1개의 문장 | 1명의 유저 |
| I went to the library to read some books | CaptinAmerica Ironman Spiderman. Dr.strange. Avengers |
- bert의 masked self-attention 을 그대로 적용
- 한 유저의 sequence에 담긴 상품/콘텐츠 list에서 일부를 masking 한 뒤 prediction 하면서 학습 진행
- 테스트 할때에는 맨 마지막 상품/콘텐츠을 예측하도록 설계
1. Introduction
[ abstract ]
기존의 한계점 L -> R 단방향성 (unidirectional) 의 단점
양방향 self-attention 기법 알고리즘인 BERT를 text sequence 가 아니라 user sequence 에 적용한 것
- 랜덤하게 마스킹한 아이템을 추측
- user sequence를 양방향 학습으로 표현
[ contribution ]
- 양방향 self attention 학습 방법을 제안 - cloze task 를 통해서
- sota 모델들과 성능 비교 - 양방향 학습방법의 효과 입증해냄
- 전반적인 ablation study (모델 부분부분을 제외하면서 학습 효과에 미치는 영향 파악하는거) 를 통해
어떤 부분이 모델 성능향상의 핵심 요소였는지 파악해냄
2. Related Work
2.1. General Recommendation
: Collaborative Filtering (CF), Matrix Factorization (MF),
two-layer Restricted Boltzmann Machines (RBM) --> netflix prize에서 제시된 모델
2.2 Sequential Recommendation
- sequential pattern :
Markov chains (MCs). Markov Decision Processes (MDPs), Factorizing Personalized Markov Chains (FPMC).
- RNN based model :
GRU with ranking loss (GRU4Rec), Dynamic REcurrent bAsket Model (DREAM), attention-based GRU (NARM)
- other NN model :
Convolutional Sequence Model (Caser)
Short- Term Attention/Memory Priority Model for Session-based Recommendation (STAMP)
2.3 Attention Mechanism
- NLP (many to many) : Transformer, BERT(transformer encoder 부분)
- Attention + Recommendation : SASRec (이번 논문과 가장 유사한 모델)
+) SASRec과 Bert4rec비교 (좌 SASRec, 우 Bert4rec)
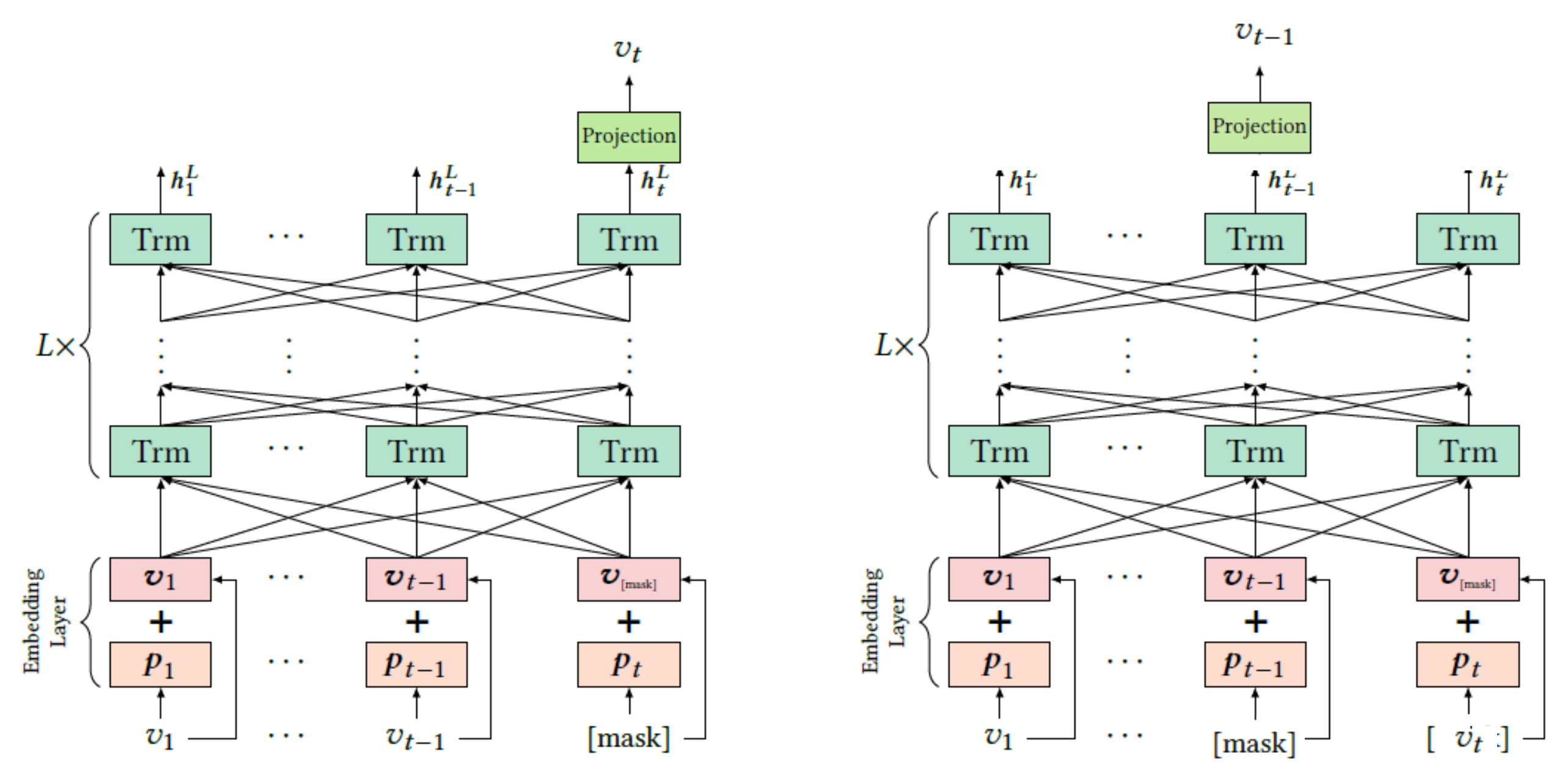
[ SASRec ]
next item을 masking - 다음 추천 아이템을 예측하는 방식 transformer의 decoder 구조를 가지고 있음
양방향이 아니라 단방향(unidirection) 모델
SASRec의 학습 과정
v1 학습 --> 예측 v2
...
v1 ~ vt-2 학습 --> 예측 vt-1
v1 ~ vt-1 학습 --> 예측 vt
문제점 : 계산량 많음 - 각 타임 step 에 따른 loss 모두 계산 (하나의 시퀀스에서 t-1 번 loss 계산)
단방향성 - vt-1 를 예측할때는 이전에 등장한 v만 참고할 수 있고 미래의 vt는 참고할 수 없음
→ 이 두가지 문제점을 보완해서 등장한 알고리즘이 - BERT4rec
3. BERT4Rec
3.1 Problem statement
기존의 유저-상품 시퀀스를 바탕으로 해당 user가 다음 상품을 선택할 확률을 최대화 하는 것

set of user |
 |
| set of items |
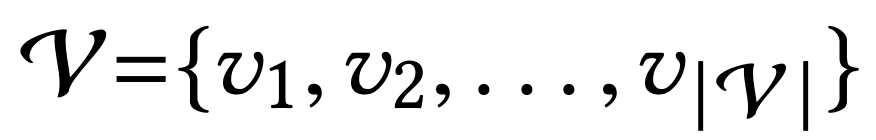 |
interaction sequence list |
 |
3.2 Model Architecture
[ L개의 transformer layer ]
트랜스포머 기반이기 때문에 각각의 층들은 모든 포지션의 represantation을 수정,
이전 레이어의 모든 정보와 정보 교환이 가능해짐
과거 RNN 계열 모델은 이전의 history hidden state만을 학습에 반영했지만,
transformer는 모든 방향에서의 정보를 다 반영
CNN 을 base 로한 caser 모델은 제한적인 필드만을 학습에 반영
3.3 Transformer Layer // 3.4 Embedding Layer // 3.5 Output Layer


t : input sequence length
h1L : 각각 transformer layer의 아웃풋 (다음 transformer layer를 적용)
모델 input : 아이템 v1 ~ vt (중간 vi 하나 masking) (위의 모델 구조에서는 마스킹을 맨 마지막 vt에 한 것)
모델 output : masking 된 item이 등장할 확률 (softmax값)
# embedding (Positional embedding)

vi : item embedding - d차원으로 임베딩된 아이템 벡터
pi : positional embedding - d차원으로 임베딩된 포지션 벡터 (아이템의 상대적 또는 절대적 위치 정보를 주입함)
--> 이 두 값을 합친 값이 transformer input
# multi head self attention



- W는 Query weight, key weight, value weight 각각 나뉨 --> 이렇게 구한 각각의 Q,K,V 값에 attention 적용
(분자의 루트 d/h 는 값이 너무 커지는 것을 방지하기 위해 스칼라(임베딩차원/head개수) 값으로 스켈링 해주는 개념 )
- multihead attention 이기 때문에 H개의 head를 가짐 → 각각의 head는 Wo 와 내적
+) self attention 이기 때문에 Query, key, value 모두 같음 (같은 유저의 item list)
- scaling 한 뒤에 다시 Q*K 에서 masking 은 0표시
- softmax 전에 mask item 부분은 큰 음수값 넣기

# position wise feed forward Network


- 각각의 head에 Feed Foward Network 적용 → 각각의 값을 Transpose → concat 한 후 다시 Transpose
- 이때 활성화 함수는 GELU (Gaussian Error Linear Unit) 활성화 함수를 사용
# Stacking Transformer Layer (Add & Norm)

- 그림 (a) 의 add & norm 부분
- 층이 깊어지면 생기는 Gradient Vanishing, Exploding 문제를 방지 - Layer normalization, Residual connection 활용
+) Layer normalization : batch가 아니라 layer를 기준으로 normalization
Residual Connection : ResNet 모델에서 나온 개념으로, 비선형 함수의 결과에 기존 인풋을 더해주는 방법
# output layer

- GELU output 값과 transpose(item embedding matrix)를 내적
원래 BERT 모델에서 E transpose 는 전체 token embedding matrix를 transpose 한 것
하지만 BERT4rec에서는 전체 item embedding matrix가 아니라 negative sampling 100개를 활용
- 내적한 값에 softmax 취해 각각의 item이 output일 확률 값으로 변환됨
[ 원래 BERT모델에서 Embedding matrix Transpose ]

+) 회색 word embedding matrix 이 100x4 라고 가정하면 (100개의 전체단어, 4차원의 임베딩)
- 연두색 matrix가 self attention의 output (마스킹된 정보만 추출)
그림에서는 row가 합쳐졌지만 실제 softmax를 계산할 때는 한 mask 행씩 연산
mask 1: (1,4) * (4,100) = (1,100) --> 전체 단어중 mask1에 해당되는 token에는 큰 logit--> softmax 확률 값으로 뽑기
mask 2: (1,4) * (4,100) = (1,100)
mask 3: (1,4) * (4,100) = (1,100)
[ BERT4REC에서 Embedding matrix Transpose ]

+) lookup table shape : (6,4) // transpose 하면 (4,6)
+) 연두matrix shape : (6,4) 라고 가정
- 연두색 matrix가 self attention 의 output
- 전체 item embedding matrix 가 아니라 정답 + negative sampling 5개의 상품만 가져옴
총 lookuptable item은 6개 (Ground True + neg 5 sample)
(1,4) * (4,6) = (1,6) --> 6개 상품 중 mask1에 해당되는 item에는 logit--> softmax 확률 값으로 뽑기
- 실제 실험에서는 두가지 조건을 따라서 negative sampling 100개
조건 1 - negative sampling은 user history sequence 에 포함되지 않으며 (유저가 사거나 본적 없는 아이템으로)
조건 2 - 동시에 다른 유저들에게는 많이 사용된 아이템으로 구성
3.6 Model Learning
- 기존 단방향 네트워크에서는 다음 상품을 예측하는 것이 학습 목표였음 [ input : v1, . . . ,vt // output : vt+1 ]
- 해당 양방향 모델에서는 미래의 정보를 가지고도 과거를 예측하는게 가능해짐
- 이 알고리즘에서는 Masked Language modeling - Cloze Task 방식을 가져와서 학습 진행
BERT cloze task에서는 한 문장에서 몇몇 단어가 masking 되어있음 -> masking 된 단어를 예측하는 것이 학습 목표
BERT4rec 에서는 단어 대신 유저가 선택한 item(user behavior)


S'u : 전체 user behavior history sequence (이때, 몇개 행동 랜덤하게 마스킹)
u*m : 랜덤하게 masked user behavior
um : 마스킹 되기 전의 user behavior (Groud Truth)
마스킹된 user behavior 가 실제 user behavior 를 예측하도록 Training
- 학습 당시에는 랜덤하게 마스킹 위치를 지정 → 시험할 때는 마지막 user behavior 에 마스킹해서 예측하도록
4. Experiments
4.1 Datasets
Beauty : 아마존 화장품 리뷰 데이터 (유저, 리뷰, 아이템) → Sparse data
Stream : 게임 리뷰 데이터 (유저, 리뷰, 아이템) → Sparse data
MovieLens(ML) : 영화 평점 데이터 → Dense data
+) 유저의 리뷰 달린 여부만으로 1,0 표기 (사용했다, 사용하지 않았다)
5점 평점 - 점수는 무시하고 시청 여부만 1,0 표기 (영화 봤다, 보지 않았다)
Feedback이 5개 이하인 유저는 삭제
4.2 Evaluation Metric
# Hit Rate (HR@K) (=Recall@K) (순서 반영x)
- 특정 유저의 선호하거나 클릭했던 모든 Item을 가져옵니다.
- 모든 Item 가운데 하나만 의도적으로 제거한다. Leave-One-Out Cross-Validation
- 남은 Item들을 가지고 추천 모델을 학습한 뒤, Top K 추천 리스트를 추출
- K개의 추천 리스트 가운데 아까 제거한 Item이 있다면 hit, 아니면 hit가 아니다.

# NDCG
| CG |  |
상위 p개 아이템에 대해서 관련도를 합한것 |
| DCG |  |
CG 공식에서 분모에 log 순서+1을 추가, 순서에 따라 log값을 나눠서 연산 즉, 앞의 순서를 잘 맞출수록 높은 점수 |
| IDCG | 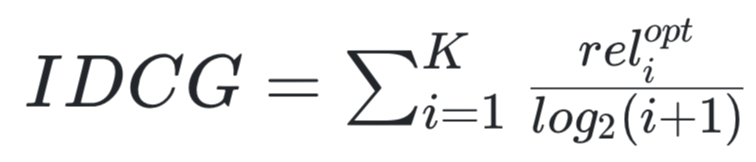 |
이상적으로 추천이 일어났을 때의 DCG값 아래의 예시에서는 Recommendation item (k=3)가 ADB로 되었을 때, DCG의 값 |
| NDCG | 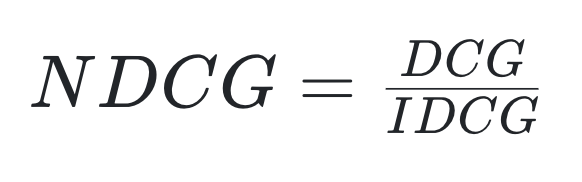 |
현재 DCG값에서 이상적인 DCG 값(=IDCG) 나눈 값 최대값은 1 (예측 DCG = IDCG) |

# MRR

사용자가 선호하는 아이템이 리스트 중 어디에 위치해 있는지에 중점을 둔 평가 기법
추천된 리스트가 있고 사용자가 선호하는 아이템이 라면, reciprocal rank(RR)는 ku이다.
10개의 추천 리스트 중 사용자가 선호하는 아이템이 7번째에 있다면 reciprocal rank(RR)는
MRR 의 최대값은 1
| user : [추천리스트] [유저의 선호도리스트] |
1: [A, B, C, D] [X, X, O, O] |
2: [A, B, C, D] [O, X, X, O] |
3: [A, B, C, D] [X, O, X, X] |
4: [A, B, C, D] [X, X, X, O] |
| user의 RR | 1/3 | 1 | 1/2 | 1/4 |
→ MRR = (1/3 + 1 + 1/2 + 1/4)/4
MRR 최대값은 1
4.3 Baselines & Implementation Details
(상세한 실험환경과 모델 내용은 논문 참고)
[ 사용한 비교 모델 ]
POP (인지도 순으로 뽑은 것), BPR-MF (Matrix Factorization + implicit feedback)
NCF (item interacion with NLP), FPMC(Factorizing Personalized Markov Chains)
GRU4Rec, GRU4Rec+, Caser(CNN based model), SASRec(단방향 self attention)
4.4 Overall Performance Comparison

- 추천되는 item 개수 K가 늘어날수록 Target item list와 겹쳐질 확률이 높으므로 성능이 향상됨
- Dense 한 데이터인 MovieLens 데이터가 확실히 나은 성능을 보임
Question 1: Do the gains come from the bidirectional self-attention model or from the Cloze objective?
양방향 셀프 어텐션, Cloze 학습 방법(여러군데 Masking) 효과가 있었나.
Answer :

- 단방향이었던 SASRec보다 효과가 뛰어남
- Cloze task 방식으로 여러군데 Masking 한 방식이 1개 Masking 한 것 보다 더 성능이 좋다.
- Mask의 적절한 개수에 대한 실험은 논문 4.6에 상세히 나온다
Question 2: Why and how does bidirectional model outperform uni- directional models? 왜 양방향 성능이 더 좋나

- 미래의 정보까지 같이 학습 하니까
- Bert4rec (a), (b)에서 보이듯이 대각선 아래, 위 각각 학습을 진행함
- layer2에서는 Masked item 을 제외한 item 끼리의 연관성 파악
4.5 Impact of Hidden Dimensionality
- hidden layer 차원 16~256 까지 조정하면서 실험
- sparse dataset 에서는 고차원 불필요
4.6 Impact of Mask Proportion ρ
- Sparse 한 데이터 : 0.6, 0.4 정도의 비율
- Dense 한 데이터 : 0.2
4.7 Impact of Maximum Sequence Length N
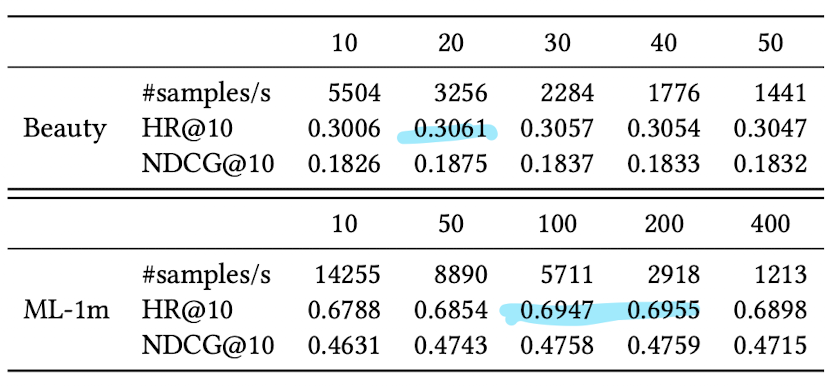
- Sparse 한 데이터 : 짧을수록 우수한 성능 20
- Dense 한 데이터 : 길수록 우수한 성능 200
4.8 Ablation Study
- Ablation Study : algorithm에서 일부 building block을 제거한 뒤에 전체 성능에 미치는 효과를 파악한 것
- Positional Embedding이 중요한 역할을 하고 있음

참고 link
BERT4rec :
https://www.youtube.com/watch?v=PKYVHGrSO2U
https://greeksharifa.github.io/machine_learning/2021/12/12/Bert4Rec/
BERT :
https://www.youtube.com/watch?v=xhY7m8QVKjo&t=5802s
추천 알고리즘 평가지표 :
https://sungkee-book.tistory.com/11
https://jyoondev.tistory.com/131



댓글