Few shot Learning, Meta learning 개념 총정리
Index
0. Few-shot learning 의 등장 배경 : " 학습 데이터가 없다 "
1. Few shot learning, Meta learning, Transfer learning 뭐가 다른데?
2. Episode training : 에피소드 방식을 통해 메타러닝을 시도
3. Meta learning 학습 기법 3가지
0. Few-shot learning 의 등장 배경 : " 학습 데이터가 없다 "
- 학습 데이터가 적은 상황에서 딥러닝 모델 구축 자체가 어려움
- 인간처럼 몇 장의 사진만을 보고도 직관적으로 분류하는 모델을 우리는 만들 수 없나 ?
- 소량의 데이터(few-shot)만으로도 뛰어난 학습을 하는 모델 만들어보자 !! --> Few shot learning 의 시작
모델이 추론하는 과정에서 소량의 데이터만 보고 추론을 할 경우 few-shot
1장의 데이터만 보고 추론을 할 경우 one-shot
0장의 데이터만 보고 (즉 Task 조건만 입력하고) 추론을 할 경우 zero-shot
용어 정리
few shot learning 관련 논문들을 읽다보면, 용어가 기존 딥러닝 논문들과 조금씩 달라서 이해하기 어려운데
간단히 짚고난 뒤 이어서 설명을 하자면..
way : 데이터 클래스의 개수 (ex. 개고양이 분류기 - 2 way classification)
shot, point : 데이터의 개수
query : test data (엄연히 따지자면 validation data)
source : train data
1. Few shot learning, Meta learning, Transfer learning 뭐가 다른데?
Few shot learning 의 목적은 말 그대로 적은 데이터로 추론이 가능하게 하는 것
그리고 이 방법으로 고안된 학습 방법이 Transfer learning 과 Meta learning

1.1 Transfer Learning
→ Pre-trained 모델을 중심으로 학습, 소량의 데이터(few-shot) 으로 재학습

대량의 데이터로 Pre-trained 모델을 생성한 뒤, 적은 Dataset을 Fine-Tuning하는 알고리즘이라는 점에 초점
Transfer learning 에서 multi task learning을 할 때는
Pre-trained 모델을 불러온 뒤 각각의 Task에 맞게 Fine-tuning 한다.
공식 : pre-trained parameter(θ)를 가져와서 New task에 맞게 optimization 목표는 New task를 위한 최적의 Φ 구하기

- 대량의 데이터로 사전 학습 모델 생성 (파란색 박스 Neural network)
- 사전 학습 모델 weight를 그대로 가져온 뒤 각 Task에 맞는 데이터 (Fine-tuning 데이터) 로 재학습해서 모델 생성 (진한 파란색 NN)
1.2 Meta-Learning
→ 여러개의 Task 를 동시에 학습 & 각 Task 간의 차이도 학습 (meta- parameter)
전체 학습 이후 소량의 데이터(few-shot) 으로도 추론 할 수 있는 범용적인 모델 생성

공식 : pre-trained parameter(θ)의 적은 update만으로도 각각의 task의 최적 파라미터(Φ)를 구할 수 있게 하는
초기 파라미터(θ)를 optimization --> 즉, New task를 위한 최적의 초기 θ를 구하기

- 학습 데이터(Source data)로 학습 한 후에 시험 데이터(Target data)로 loss 계산
- 계산된 loss를 초기 모델(Learner, Meta-Learner)에 최적화
- 여러개의 Support data, Query data 로 이 과정을 반복
즉, 메타 러닝 학습 과정에서는 전체 데이터를 여러개의 Support data, Query data로 쪼개는 과정이 필요하다.
이 방법 중 하나가 에피소드 학습 방법이다.
2. Episode training : 에피소드 방식을 통해 메타러닝을 시도
2.1 개념
[ 기존 방식 ]
쥐, 소, 호랑이, 토끼, 용 구분하는 이미지 분류기를 만들고자 한다면 (각 클래스별 데이터 100개)
쥐, 소, 호랑이, 토끼, 용 각각 80개는 학습해 5클래스 분류기를 만든뒤
쥐, 소, 호랑이, 토끼, 용 각각 20개 시험 데이터로 성능을 평가한다.
| 쥐 | 소 | 호랑이 | 토끼 | 용 | |
| 학습 | 80 | 80 | 80 | 80 | 80 |
| 시험 | 20 | 20 | 20 | 20 | 20 |
[ 에피소드 학습방법 ] : 한번에 쥐, 소, 호랑이, 토끼, 용 모든 클래스를 활용하지 않는다.
Task 1 : {쥐, 소} 클래스 분류기
Task 2 : {호랑이, 토끼} 클래스 분류기
Task 3 : {토끼, 용} 클래스 분류기
→ 이런식으로 분류기를 쪼갠 뒤, 완전히 새로운 데이터 (뱀,말, 양)으로 분류 성능 확인하는 방식이다.
2.2 에피소드 학습 방식
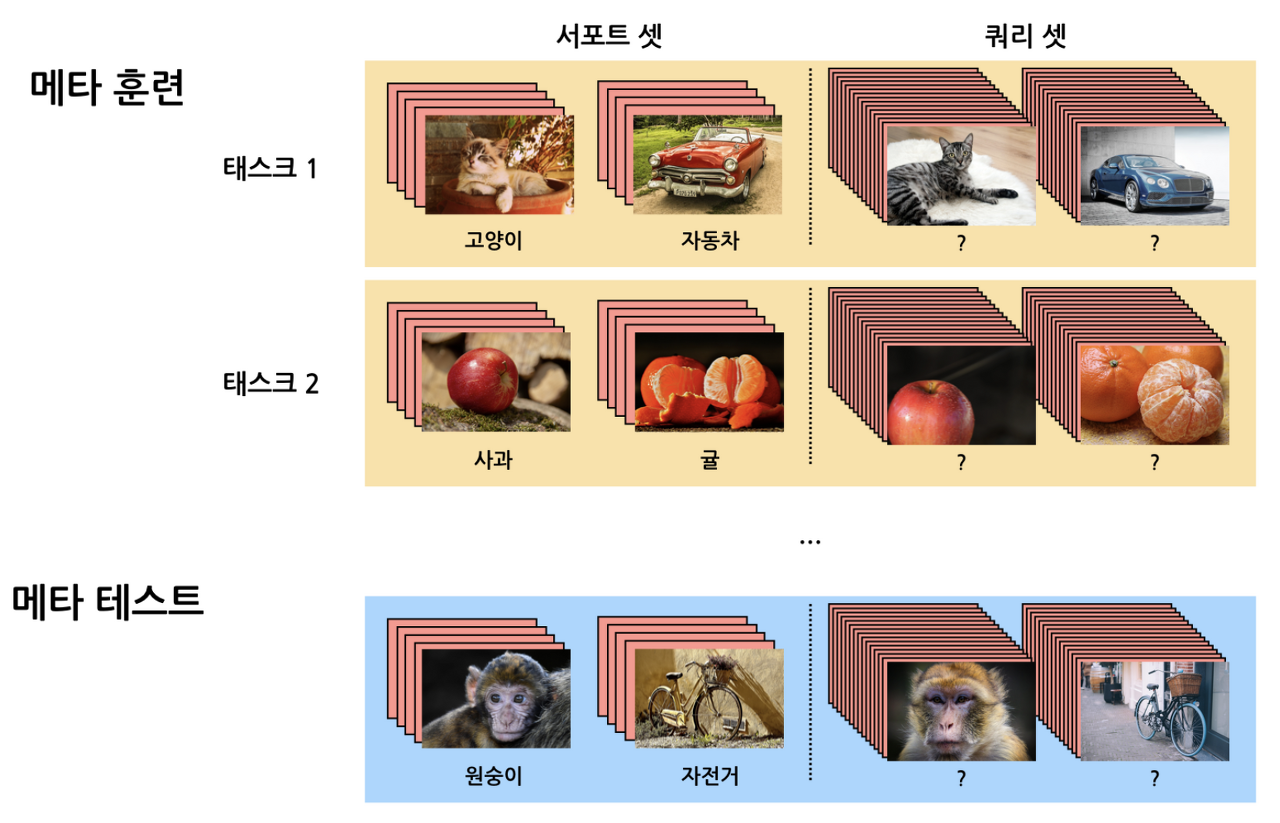
1) Train - test data split
전체 학습 데이터를 메타 훈련(Meta-train dataset), 메타 테스트(Meta-test dataset) 으로 나눈다.
이때 Meta-test에 구성된 데이터 클래스(원숭이, 자전거)는 Meta-train 에 등장하지 않은 클래스다.
2) Task Sampling
메타 훈련(Meta-train dataset) 데이터를 각 Task 데이터로 쪼갠다
전체 클래스 중 일부 클래스(Class1,2) 데이터가 Task1에 샘플링
여기서 각각의 Task 를 우리는 "Episode"라 부른다.
3) Support Query dataset split
각 Task 별 데이터를 다시 Support set(training set), Query set(test set) 으로 샘플링
(→ 기존 딥러닝 학습 방식과 마찬가지로 이 둘의 데이터는 겹치지 않음)
4) Task Training : 각각의 Task로 학습을 진행하며 모델 생성한다.
5) Meta test Evaluation :
생성된 모델에 Meta-test의 Support 셋으로 새로운 이미지 클래스 학습시키고,
최종적으로 Meta-test Query 셋을 분류해내는 것이 목적 !
⇒ 목표
학습에 활용되지 않은 클래스의 데이터(Meta-test)에서도
일부 Meta-test support 데이터로 훈련한 뒤, Meta-test query 데이터를 구분할 수 있는가
그리고 여기서 다양한 학습 방법들이 고안되는데 크게 3가지의 학습 기법으로 분류가 된다.
3. 메타러닝의 학습 기법 3가지
메타러닝에서는 각 Task가 최적의 Parameter 가 다름 (ϕ1, ϕ2,....)
따라서 모든 Task parameter (ϕi) 를 추정하는건 의미가 없음
중요한건, 데이터 특성과 ϕi 사이의 정보(θ) 를 학습 ⇒ 추후 새로운 데이터가 들어오면 θ를 이용해서 추정 ⇒ how?
𝜃를 어떻게 사용하는지에 따라 접근 방법이 나뉜다.

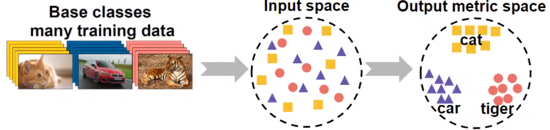
3.1 Metric-based Approach : 거리 기반 학습 기술
- metric learning 에서 중요한 개념 2개 - embedding function, Distance
- 학습 데이터를 저차원의 공간에 Mapping (임베딩)
- 새로운 데이터가 들어오면 저차원 공간에 임베딩 → 임베딩 공간에서 가장 가까운 클래스로 분류
- 관련 연구 : 샴 네트워크, matching network, prototype network
3.2 Model based apporach : 모델 기반 학습
- 모델 내부나 외부에 기억장치(memory)를 둠으로써 학습 속도를 조절한다.
- 모델은 몇번의 Training step 만으로도 파라미터 빠르게 찾는게 가능해짐
- 관련 연구 : Memory network, NTM, MANN
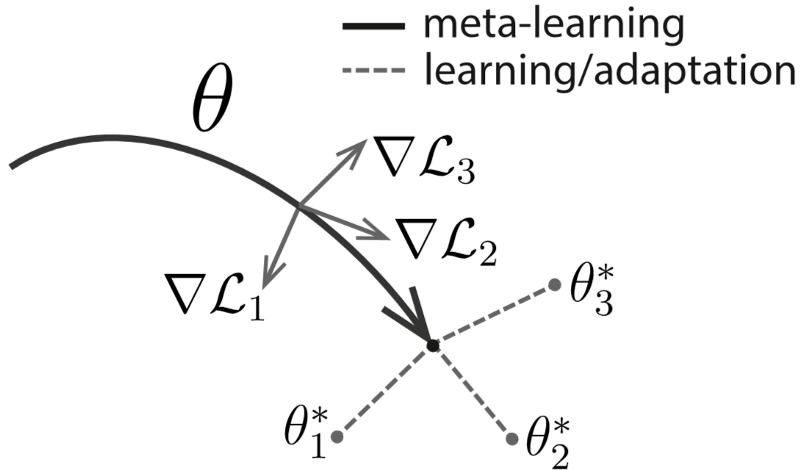
3.3 Optimization-based Approach : 최적화 기반 학습
- 각각의 task의 최적 파라미터(π)를 구할 수 있게 하는 초기 파라미터(θ)를 optimization
- 관련 연구 : MAML, First order MAML, Reptile
각각의 기법에 대한 자세한 설명은 관련 연구 논문 리뷰를 통해 정리 해보려 한다 !
참고 link :
https://www.kakaobrain.com/blog/106
https://velog.io/@tobigs-gm1/Few-shot-Learning-Survey
https://talkingaboutme.tistory.com/entry/DL-Meta-Learning-Learning-to-Learn-Fast
https://meta-learning.fastforwardlabs.com/



댓글