www.youtube.com/watch?v=gmoEgeRPOoQ&list=TLPQMDExMTIwMjANBSFBbypvBw&index=2
0. 음성 인식 ?
[ STT 모델 개발의 pipeline ]

1. 로우 데이터 음성 입력
2. 특징 추출
3. 음성 모델 - DNN, RNN
4. 디코더 ** : 음성 신호를 텍스트로 맵핑
- 음향 모델, 발음 사전 --> 텍스트로 변환
- 언어 모델 --> 텍스트를 벡터로 변환 (기계가 이해)
[ 음성인식 모델의 발전과정 ]
STT -> LAS -> online streaming recognition (RNN-Transducer, NT, MoChA)
[ 음성 분야의 다양한 태스크 ]
- Audio Auto Tagging :
지금 소리가 어떤 상황인지를 tagging - multi class, multi label 분류문제
모델 구조 : 음성 입력 -> DNN(피쳐 추출) -> 분류
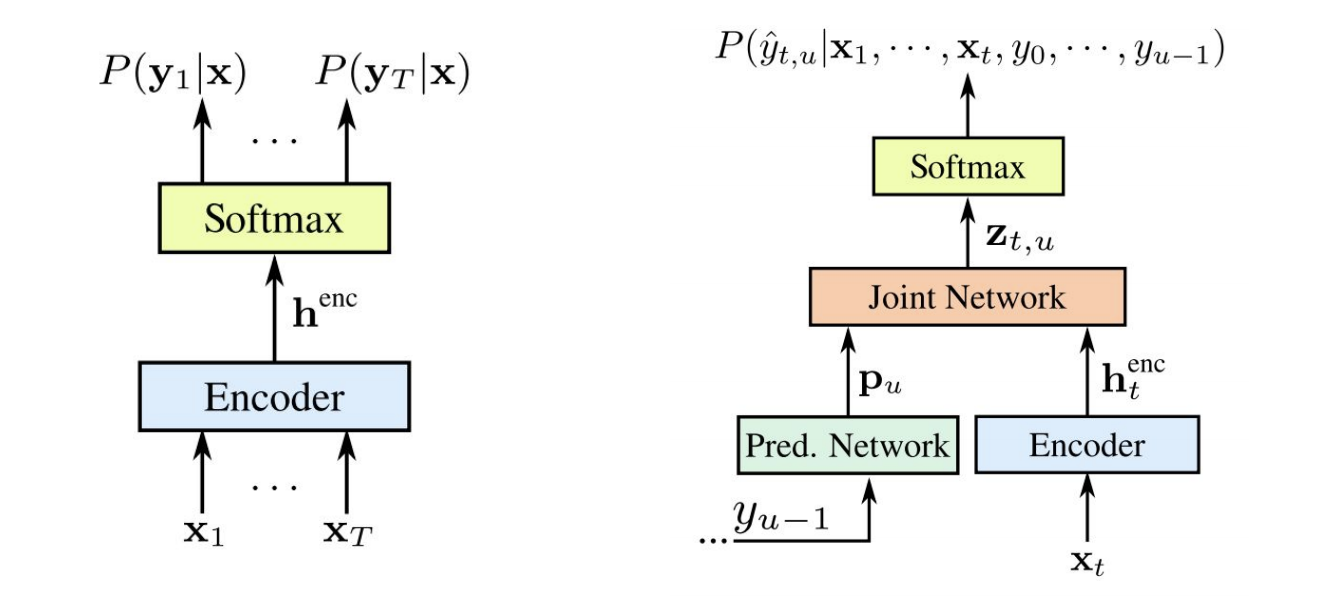
1. CTC
input audio - output text 사이에서 맵핑을 하는 것
 |
 |
이렇게 입력이 된 오디오를 잘개 쪼갠뒤 ailghtment 과정을 거친다.
이때 오디오에서 빈 부분은 임의의 토큰 (입실론)을 넣어주고
이후 아웃풋과 맵핑을 하게 된다. 그리고 여기서 핵심 개념은 DP
 |
 |
핵심 개념은 alignment 의 조건들 HELLO 라고 한다면
- 무조건 시작은 H 다 (앞에 묵음이 등장하더라도 처음 음성은 아웃풋의 첫 캐릭터인게 당연함)
- L 직전에 등장할 수 있는건 묵음 아니면, E 이다 (H, O 는 될 수 없음)
- Encoder (RNN계열 ㅂ모델) 통과한뒤, 인풋 음소 단위와 전체 각각 텍스트 토큰일 확률을 구하는 셈.
그중 가장 큰놈이 상응하는 텍스트라 생각하면 됨.
2. LAS

Listener, Attention, 그리고 Speller로 나눠짐
3. oneline model
스트리밍 실시간으로 음성을 처리할 수 있도록 설계된 언어 모델




댓글