자연어처리 임베딩 모델들의 전체 컨셉 개념을 복습해보겠다.
이전 모델에 비해서 뭐가 다른지 간단하게만 정리해 둔거니 보다 자세한 자료는 참고링크에서 공부하시길
[ 임베딩 ]
인코딩은 어떤 단어 혹은 대상을 [0,1,0,0,0,0 ... ] 등 0과 1 둘 중 하나의 숫자로 표현하는 개념
임베딩은 이러한 [0,1,0,0,0,0 ... ] 벡터를 --> [0.1,0.2,0.5 ] 등 dense 한 벡터로 만들어줌
그럼 저 벡터를 어떻게 만드냐? 그거에 따라 임베딩 모델들 이름이 달라지게됨
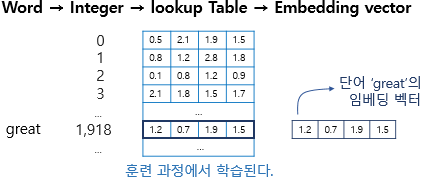
0. Neural Probabilistic Language Model : 이전 단어들을 통해 다음 등장 단어 확률을 계산 !
word2vec의 시초같은 느낌
다음 등장할 단어의 확률을 계산하고, 이를 최대화 하는 방식으로 학습 진행

단점 : 계산복잡성 (Computational Complexity)
- 임베딩으로 사용하는 행렬 CC 외에도 HH, UU, bb, dd 등 다른 파라미터들까지 업데이트를 해줘야 한다.
- 따라서, 과적합 (Overfitting) 이 발생할 위험이 높다.
- 이러한 문제점을 극복하기 위해 학습 파라미터를 줄이는 방향으로 제시된 모델이 Word2Vec이다.
1. word2vec : 동시에 등장하는 단어들을 벡터공간에서 가깝게, 아니면 멀게 !

- skipgram (중간단어로 주위단어 예측하며 학습), cbow (주위 단어로 중간단어 예측하며 학습) 가 있다.
skipgram 이 디폴트다
- 중간 단어를 통해 주변단어의를 잘 맞추는 과정을 거치면서 hidden layer 의 weight matrix 가 조정된다
- 학습을 마친후 이 weight matrix에서 각 단어에 상응하는 벡터를 추출할 수 있게 된다.
- 여기 weight matrix 에서 각 벡터의 의미는, 각 단어가 어떤 단어와 윈도우 사이즈내에서 동시에 등장했는지 벡터 가중치로 수치화 된 것이며, 이를 통해 단어간의 유사도 파악이 가능함
- negative sampling : 반대로 윈도우 사이즈 내에 절대 같이 등장하지 않는 단어 토큰 끼리는
weight matrix에서 각 토큰 간의 벡터 값 거리를 멀리 떨어트린다.

2. fasttext : word2vec 을 기반으로 하되, 단어를 쪼개서도 임베딩 하는 기법
가장 큰 차이점은 Word2Vec은 단어를 쪼개질 수 없는 단위로 생각한다면,
패스트텍스트는 하나의 단어 안에도 여러 단어들이 존재하는 것으로 간주
즉 내부 단어(subword)를 고려하여 학습한다.
apple is good 이면 --
word2vec 에서는 [ apple, is, good ]
fasttext 에서는 [ ap, app, ppl, ple, le, apple, is, goo, ood, good ]
보라색 부분은 쪼개진 것이며 해당 예시는 tri gram 기준, 언더바 토큰 처럼 완전한 애들도 넣어줌
장점 : 오타나 합성어(Birthplace) 같은거 잘 쪼개서 학습,
OOV (out of vocabulary) 문제도 어느정도는 해결 가능
단점 : 너무 쓸 때 없는 토큰들도 같이 학습 app, ppl, ple, --> 의미없잖으...
3. LSA : 문서 단어 행렬에 특이값분해 SVD
문서 - 단어 행렬 문서 별 등장하는 단어 여부 체크한 매트릭스

저 위의 매트릭스를 SVD 특이값분해 한 것
4. glove : 카운트 기반과 예측 기반을 모두 사용하는 언어모델.
LSA, word2vec 다 비판하면서 등장
LSA :
장점 - 말뭉치 전체의 통계적인 정보를 모두 활용하지만,
단점 - LSA 결과물을 가지고 단어/문서 간 유사도를 측정하기는 어려운 단점을 지님.
word2vec:
장점 - 벡터공간에 임베딩된 단어벡터 사이의 유사도를 측정은 잘하지만
단점 - 사용자가 지정한 윈도우(주변 단어 몇개만 볼지) 내에서만 학습/분석이 이뤄지기 때문에
말뭉치 전체의 공기정보(co-occurrence) 노반영
GloVe : 임베딩된 두 단어벡터의 내적이
말뭉치 전체에서의 동시 등장확률 로그값이 되도록 목적함수를 정의.
(their dot product equals the logarithm of the words’ probability of co-occurrence) “
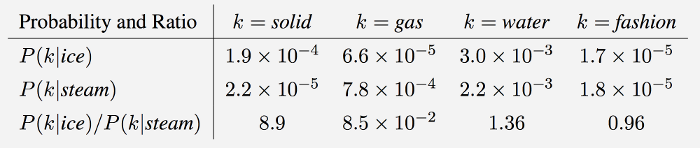
LSA의 한계를 보완해 각 단어들간의 내적이 동시 발생 빈도가 되게 하려 했음
word2vec의 한계를 보완해 윈도우 사이즈 단어간의 유사도가 아니라 전체 말뭉치 안에서 단어간의 동시 발생 빈도를 구하게끔
이 때까지 등장한 워드 벡터 값은 학습 과정 이후 도출된 결과 값을 활용하는 것으로 --> 다 고정된 벡터값
하지만 이후로 등장하는 학습 방법은 대체로 그 임베딩 학습 모델 자체를 자연어처리 태스크에 활용하는 것
쉽게 설명하면 이전에는
before) traindata --> word2vec traindata 벡터값으로 변환 --> DNN (감정분류) --> 긍정 / 부정
after) traindata --> 언어모델 + DNN (감정분류) --> 긍정 / 부정
즉 언어 모델위에 자신이 풀고자하는 태스크에 맞게 레이어를 쌓는 방식임
이러한 방식을 language model, 전이학습기반 language model 이라고도 부름
최근 많이 사용되고 있는 언어모델은 총 3개 Elmo, GPT 시리즈 그리고 BERT다 (아래의 표에서 GPT는 GPT1기준으로 작성됨)
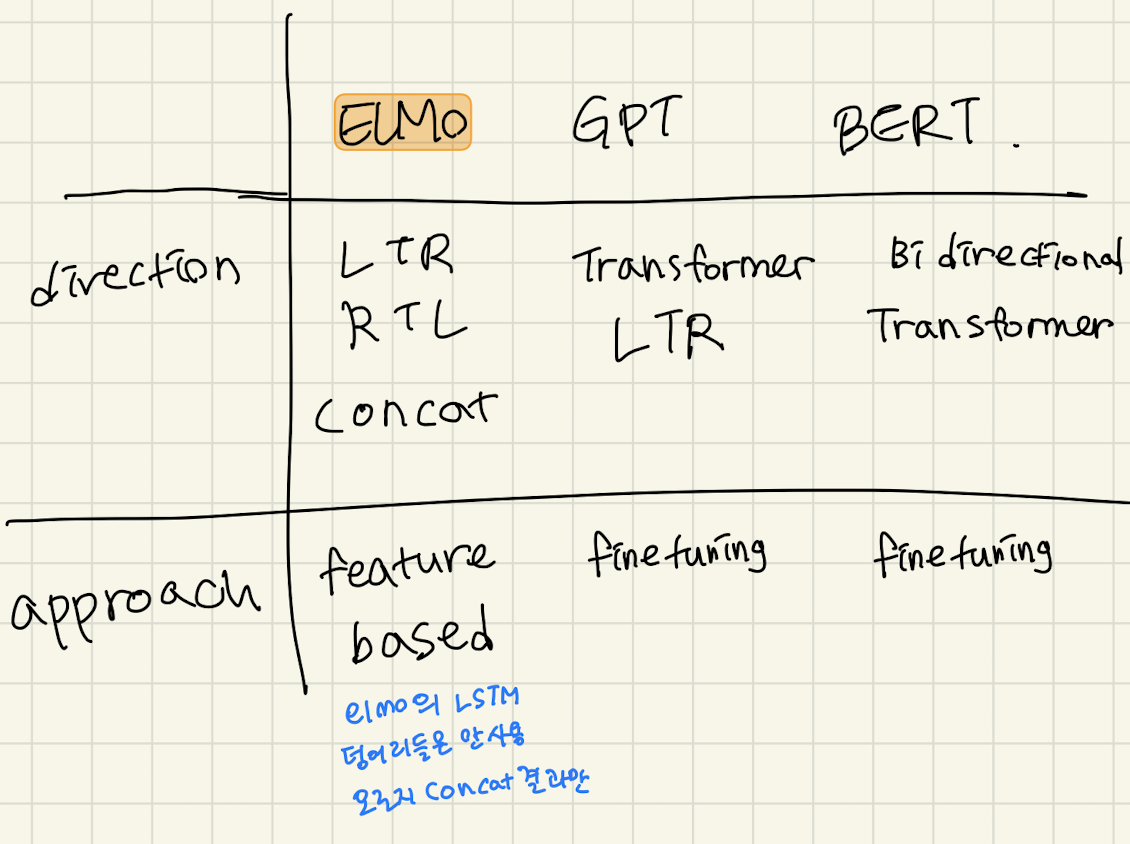
각 언어 모델의 학습 데이터 양, 학습 파라미터 갯수, 필요로한 컴퓨팅 파워
5. ELMo - 양방향 LSTM 기반의 언어모델
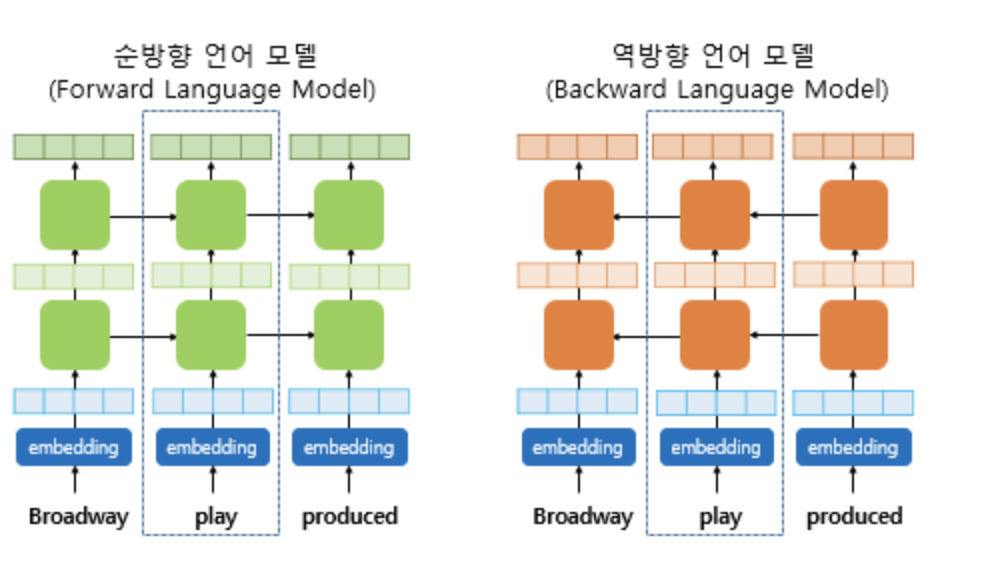
1) Many to many 구조로 LSTM 쌓기
2) 각 층의 output 을 concat
3) 각 층별로 가중치를 줌 ==> 이건 task 에 맞도록 fine-tuning 시켜주는 학습 파라미터 ****
4) 각 층의 출력값을 모두 더해더해
단점 :
- 그럼에도 불구하고 결국 각 층의 가중치를 활용하는 거기 때문에 feature based **
- 단방향 단방향 을 이어붙인걸 과연 양방향이라고 주장할 수 있나
- 두 방향을 이어붙인거 너무 shallow 한 네트워크
** shallow network 와 deep network 의 차이
- Shallow에서는 노드의 수가 exponentially 증가해서 문제
deep network 는 말그대로 레이어를 너무 깊게 쌓은것
elmo 에서는 레이어를 3개 밖에 쌓지 않기때문에 네트워크가 깊지는 않지만,
LSTM 이 각 토큰 길이 *2 (양방향) 으로 쓰이기 때문에 shallow network 문제가 발생 !
6. BERT
* 등장 :
기존 언어모델들 양방향이라고 주장하긴 했지만 sequential 한 성격 버리지 못함
단방향 + 단방향 형태는 양방향이 될 수 없음
* 핵심 컨셉 :
전체 문장에서 일정 토큰(단어)에 구멍을 뚫은뒤 그걸 추론하는 식으로 학습시키자
그럼 공부할때 그 이전 등장 단어도 이후 단어도 같이 학습하지 않나
그리고 여기서 학습에 활용된 모델은 Transformer (BERT를 이해하기위해선 Transformer를 읽어야함)
1) Transformer?
기존 RNN, LSTM 기반 seq2seq 모델들이 겪는 Gradient Vanishing 문제를 해결하기 위해
디코더 인퍼런스 때 마다 인코더의 정보를 주는 Transformer 구조가 등장했고
BERT 는 이 Transformer에서 encoder 부분 (self attention) 의 학습 과정을 따온 언어모델
여기 참고
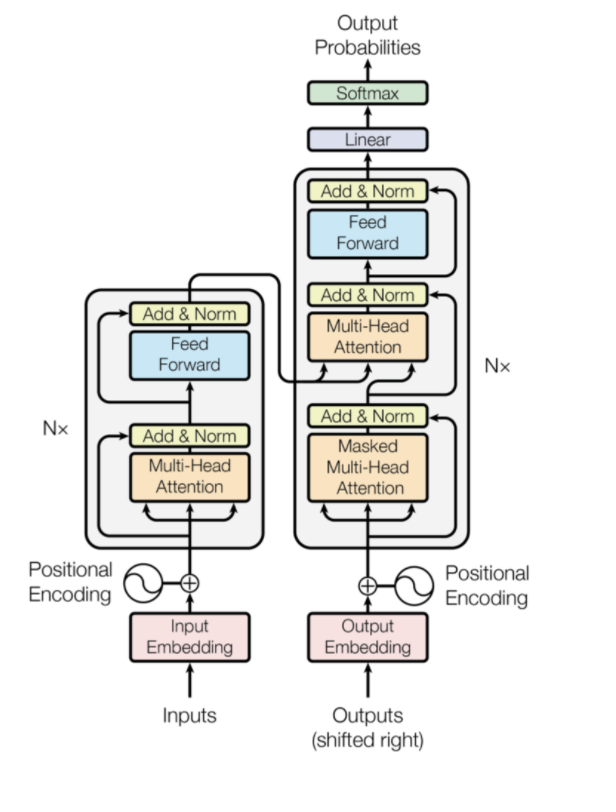
2) attention
multi head attention 과 Self attention 의 핵심은 그거다
multi head attention 은 인풋 아웃풋이 다른 것
Self attention 은 인풋 아웃풋이 같은 것
즉 query , key , value + task 로 설명하면
multi head attention 은 인코더 전체 학습 과정을 거친 값이 key 로 들어가는 반면
Self attention 은 인코더의 attention 은 결국 인코더 디코더 구조에서
인코더 전체 토큰과 디코더 입력 토큰의 유사도를 기반으로
3) BERT 의 두가지 학습 방법
BERT는 크게 두가지 학습 과정을 거쳐 만들어진 모델입니다.
첫번째는 마스크 랭귀지 모델과 두번째는 다음 문장 예측
- masked self attentnion (마스크 랭귀지 모델)
마스크 랭귀지 모델의 경우에는 기존 언어모델들은 1,2,3,4번째 토큰을 입력받은 뒤
5번째 토큰을 예측하는 식으로 일방향성을 추구했다면
BERT 의 경우는 3번째 토큰을 예측하기 위해 1,2,4,5 번째 토큰
그러니 양방향의 토큰이 모두 사용되면서 학습이 진행

- 다음 문장 예측
나아가 주어진 텍스트에서 연이어 나온 두 문장의 연속 여부를 판단하는 학습과정도 거치면서
문장 단위에서의 연속성, 문맥도 파악
'Study > NLP (Natural language processing)' 카테고리의 다른 글
| [NLP] Pytorch 영어 뉴스 텍스트 데이터 분류 (AG news dataset) (1) - 전처리 (0) | 2022.04.12 |
|---|---|
| 한국어 텍스트 말뭉치 (도메인별 나눠져있음) (0) | 2020.10.24 |
| [NLP] Attention과 Transformer (1) | 2020.10.21 |
| [NLP] LSTM, GRU의 한계와 Attention 등장(201015) (0) | 2020.10.15 |
| GPT- 한국어 적용 (0) | 2020.08.13 |


댓글