Q. LSTM GRU 의 한계는 뭔가요 ?
Q. Attention 은 무엇인가요 ?
1. LSTM GRU 의 특징과 한계
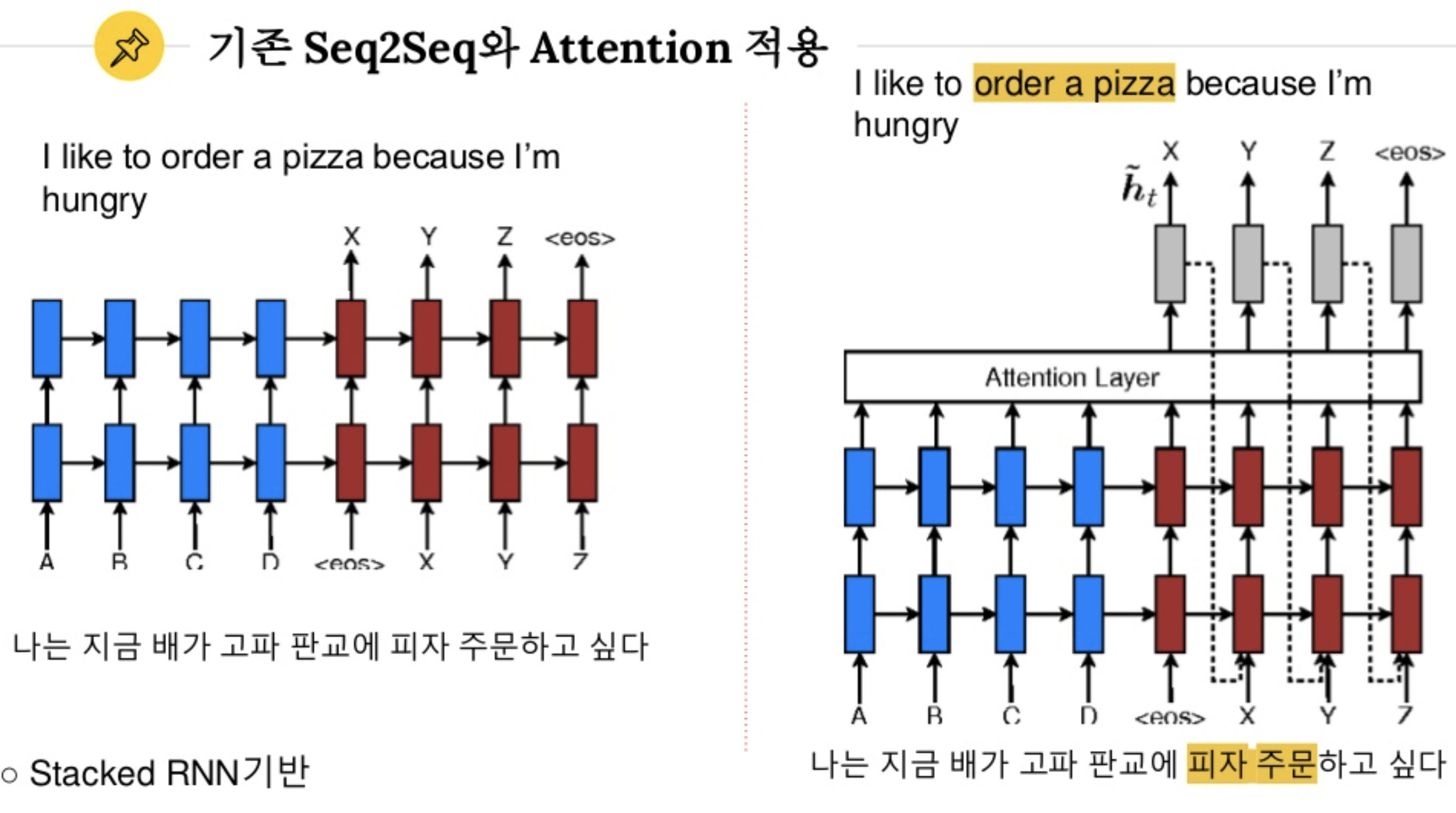
seq2seq 모델은 인코더에서 입력 시퀀스를 컨텍스트 벡터라는 하나의 고정된 크기의 벡터 표현으로 압축
디코더는 이 컨텍스트 벡터를 통해서 출력 시퀀스를 만들어냄

RNN에 기반한 seq2seq 모델에는 크게 두 가지 문제가 있다.
첫째, 하나의 고정된 크기의 벡터(context vector) 에 모든 정보를 압축하려고 하니까 정보 손실이 발생
둘째, RNN의 고질적인 문제인 기울기 소실(Vanishing Gradient) 문제가 존재
이를 극복하기 위해 LSTM, GRU는 Ct를 추가했지만 그럼에도 불구하고....
따라서 디코더에서 output 을 뽑아낼때, 인코더의 최종 결과물인 context vector에만 의존하지 않고
중요한 인코더의 정보만 활용할수는 없을까... 그것이 바로 어텐션 !
2. Attention 의 등장
핵심 개념은 맥락을 보고 이 단어에 집중해 !
디코더과정에서 인코더의 정보를 context vector 뿐만 아니라 attention 이라는 과정을 추가하여 정보를 제공한다.
가령 인코더 디코더 번역 문제라고 한다면,
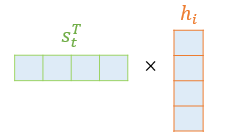
1) 디코더 구조에서 특정 토큰이 입력되었을 때, 인코더 입력 토큰에 디코더 특정 토큰을 내적한다.
( 이는 전체 인코더 입력 토큰 과 디코더 토큰이 얼마나 유사한지를 구하는 과정임 )
2) 그리고 소프트 맥스를 거친 값을 각 인코더의 hidden state 와 곱하고 최종적으로 더 함
즉, 디코더 구조에서 "suis" 를 입력 토큰 I am a student 각 토큰과의 유사도를 구하고
그 유사도와 각 입력토큰의 hidden state를 곱해 suis를 표현해내는 거다.
따라서 구해지는 값은
= ( 0.1 * I의 hidden state) + (0.05 * am 의 hidden state) + (0.05 * a 의 hidden state) + (0.8 * student 의 hidden state)
해당 계산 과정을 보다 자세히 설명해보겠다.
3. Dot product Attention **
여기선 Dot - product attention 이고, 이후에 Transformer에 가면 Multi head attention 이라는 놈도 등장하는데
우선 이번 포스팅에서는 Dot - product attention 만 정리해보자면,

해당 문제는 기계 번역 문제다 인코더에서 영어를 입력하고, 디코더에서 불어를 입력하는 seq2seq 구조
0) 인코더 과정을 쭉 거친다 -> 디코더 과정을 거친다.
이때 디코더에서 토큰을 입력할때 !!! Attention score를 구함 (그림에서 초록색 땡그라미)
원래 디코더구조에서 현재 시점 t에서 필요한 입력값 ? 이전 시점인 t-1의 은닉 상태와 이전 시점 t-1에 나온 출력 단어
어텐션 구조에서는 ? 이전 시점인 t-1의 은닉 상태와 이전 시점 t-1에 나온 출력 단어 + Attention score
1) attention score 구하기
디코더 구조에서 "suis" 를 입력 토큰 I am a student 각 토큰과의 유사도를 구하고
그 유사도와 각 입력토큰의 hidden state를 곱해 suis를 표현해내는 거다.
가령 suis 와 I am a student 의 유사도 (내적 결과 값) 각각 40, 20, 20, 320 이라고 한다면.
이걸 softmax를 거쳐 합이 1인 확률 값으로 바꾼다. 0.1 , 0.05, 0.05, 0.8
그리고 이 각각의 확률 값을 해당 인풋 토큰의 hidden state 와 내적하여 합해줌

Attention score = ( 0.1 * I의 hidden state) + (0.05 * am 의 hidden state) + (0.05 * a 의 hidden state) + (0.8 * student 의 hidden state)
2) attention score 를 디코더 t 시점의 hiddenstate 와 연결

저기서 attention value 가 방금 우리가 구한 Attention score 다
여기에 디코더 에서 suis 토큰이 LSTM 을 통과하여 얻은 hidden state를 concat 연결시킨다.
3) 연결후 다시 W(x) + b

이렇게만 연결을 한다면 사실상 학습 파라미터는 없다. (중간에 내적만 할뿐 weight matrix 등장 안 함)
하지만 연결한 후 가중치 매트릭스(weight matrix )를 곱해주고 tanh 함수를 거치는 신경망 연산을 추가한다.
4) 해당 아웃풋을 다음 디코더 토큰의 인풋으로 사용한다.
==> 핵심은
원래 인코더 디코더 구조에서 디코더는
오로지 인코더를 모두 거친 context vector 에만 의존하고,
지금 스텝의 디코더 아웃풋(St-1) 만이 다음 스텝 디코더 인풋(St)의 정보가 되었지만,
Attention에서는 지금 스텝의 디코더 아웃풋(St-1) + 이전 스텝의 어텐션 스코어(at-1) 가 함께
다음 스텝 디코터 토큰 예측(St)에 입력으로 들어감
어텐션 스코어는 인코더의 모든 토큰과 지금 스텝의 디코더 아웃풋(St-1) 의 내적 / 소프트 맥스의 총합
==> 한계는 ?
이 과정에서 RNN 의 hidden state 가 꼭 필요한가 다른 걸로 대체할 수는 없을까?
attention score를 구할때 막판에만 weight matrix 를 쓰는데,
중간중간에도 weight matrix 를 쓰면 학습 파라미터가 많아져서 성능이 더 올라가지 않을ㄲㅏ?
이 컨셉이 바로 Multi head attention 을 기반으로 한 Transformer 다
그것은 다음 포스팅에서 . !
'Study > NLP (Natural language processing)' 카테고리의 다른 글
| 한국어 텍스트 말뭉치 (도메인별 나눠져있음) (0) | 2020.10.24 |
|---|---|
| [NLP] Attention과 Transformer (1) | 2020.10.21 |
| GPT- 한국어 적용 (0) | 2020.08.13 |
| Fastbert 논문리뷰자료 (0) | 2020.08.08 |
| 코드 해석하는 AI (0) | 2020.08.07 |

댓글