[Deep learning][논문리뷰] Tabnet : Attentive Interpretable Tabular Learning
* concept
입력된 table (tabular) 데이터에서 Feature를 masking하며 여러 step을 거쳐서 학습
—> 각 step별 feature들의 importance 파악 (설명력 확보)
—> masking 으로 중요한 feature 들만 선출해서 학습하여 성능 향상 (모델 고도화)
* Tabnet 관련 link
논문 paper : https://arxiv.org/pdf/1908.07442.pdf
tabnet pytorch 버전 문서 (pytorch_tabnet documentation) : https://pypi.org/project/pytorch-tabnet/
tabnet pytorch 버전 깃헙 (pytorch_tabnet github) : https://github.com/dreamquark-ai/tabnet
1. Introduction
# contribution
1) 전처리 과정을 거치치 않은 raw data로도 end-to-end 학습이 가능하다
2) sequantial attention 과정에서 각 스텝마다 중요한 feature를 선별함으로써
각 과정에서의 모델 해석과 성능 향상이 가능해진다.
3) 다양한 도메인의 데이터에서 다른 테이블 학습 모델과 비교 했을 때 분류/회귀 문제에서 우수한 성능을 보인다.
4) masking 된 feature를 예측하는 (tabnet decoder) 비지도 학습을 진행하여 우수한 성능을 보였다.
2. Related work
# 기존의 feature selection VS tabnet 의 end-to end
- Lasso Regularization, instance-wise feature selection(개별로 고르는 방식), actor-critic framework 방법들이 사용됨
하지만 해당 방법들은 hard feature selection (칼럼을 그대로 제외하는 방식)
- tabnet에서는 soft feature selection 이 가능해짐
위의 전처리 기법이 아니라 end-to-end 기법을 사용하기 때문에 feature seletion 과정이 학습 과정안에 포함되므로
# Tree based learning :
- Decision tree 는 Tabular(table) 데이터에 빈번히 활용된 알고리즘
강점 : information gain 계산을 통해 global 하게 중요한 feature를 선별해 내는 것
- 나아가 Decision tree기반 모델에 앙상블을 적용한 XGB, LightGBM 이 대부분의 대회에서 우수한 성능을 보임
- 우리 실험결과는 트리 기반 모델들이 딥러닝과 함께 활용되었을 때 더 우수한 성능을 보인다는 걸 입증함
# intergration of DNNs into DTs (딥러닝(DNN) 과 트리 기반 모델의 결합)
- DT를 DNN block 으로 표현하려 했던 과거의 연구는 중복되는 연산으로 인해 비 효율적인 학습 방식이었음
- Soft (neural) DT 에서는 (미분 불가능한 분할 방법 대신) 미분 할 수 있는 결정함수를 사용했음
그러나 feature selection 효과까지 잃으면서 큰 성능 개선을 보이지 못함
3. Tabnet for Tabular Learning
3.0 Conventional DNN (Tabnet 에서 base concept)
------ 실제 Tabnet 구조 ---------
3.1 Encoding architecture
+) Mask 모델 해석
3.2 Decoding architecture (Tabular self-supervised learning)
# Conventional DNN : tree 기반 모델의 변수 선택 특징을 딥러닝 구조에 적용한 것
딥러닝 알고리즘 안에 feature selection 이 있는 것 --> conventional DNN을 통해 !
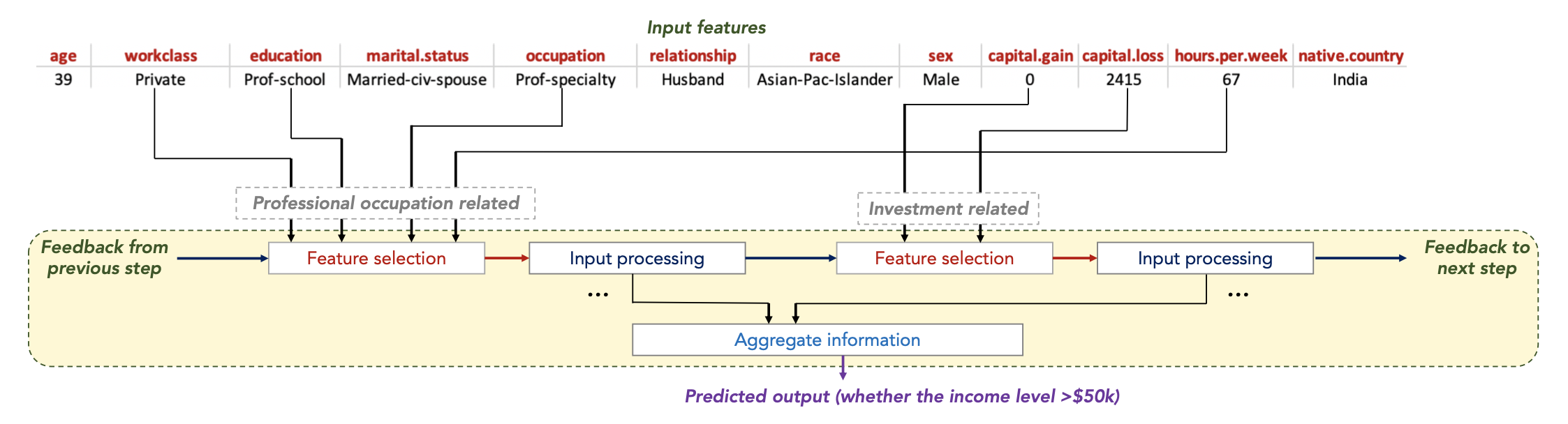

- feature 몇개 고른 뒤 -> input processing
- 이 과정 반복한 뒤 각 step 에서 나온 information을 취합해 학습 모델에 input
- feature selection 에 활용된 방식이 아래의 Conventional DNN
→ 해당 컨셉은 각각의 스텝 마다 feature selection 을 시도하는 것임
coefficient (계수)가 각 feature의 비율을 결정 - 이를 통해 general 한 선형 결합의 decision boundary를 형성

- 좌측 Mask Block : 첫번째 변수를 제외한 나머지 변수에 대해서 masking (첫번째 변수만 학습에 활용)
- 우측 Mask Block : 두번째 변수를 제외한 나머지 변수에 대해서 masking (두번째 변수만 학습에 활용)
- 결국 위 이미지의 FC 네트워크에서는 하나의 변수만이 활용되는 것임
(결정 경계를 형성해 가는 Tree algorithm 과 유사한 컨셉 )
- 이러한 컨셉을 해당 모델 Tabnet에서도 적용 !
Tabnet은
- (DNN의 임베딩 과정이 있기 때문에) sparse instance-wise feature selection 이 가능함
- sequential 한 multi step 구조를 갖추고 있고 이를 통해 각 피쳐 반영 비율을 조정할 수 있음
- (DNN - activation function) 비선형 학습 과정을 통해 성능 향상
- 앙상블 알고리즘을 딥러닝으로 구현함으로써 더 나은 성능을 보임
3.1 Encoding architecture


[ 전체 과정 요약 ]
attention layer 차원, prediction layer 차원은 hyperparameter
D 는 입력 데이터의 차원 (feature 의 개수)
B 는 batch size
⓵ feature transformer : batch norm을 거친 input data를 임베딩 (FC + BN + GLU) → $\mathrm{f_{0}}$
- input shape : $B\times D$
- output shape : batch * attention layer 차원
⓶ step1 - Attentive transformer : 학습 가능한 마스크 matrix 생성 (step 1 학습에 활용 안되는 column 0으로 masking)
- input shape : batch * attention layer 차원
- output shape : batch * feature 개수 (일부 칼럼 0으로 masking) $M[1] = R^{B\times D}$
⓷ step1 - Masking : D차원의 마스크 matrix 와 feature transformer의 output 곱함
⓸ step1 - Feature transformer : Masking 된 data를 임베딩 (FC + BN + GLU) → $\mathrm{f_{1}}$
- input shape : batch * feature 개수 (일부 칼럼 0으로 masking)
- output shape : batch * (prediction layer 차원 + attention layer 차원)
$\mathrm{f_{1}} ( M[1] \cdot \mathrm{f_{0}})$
⓹ step1 - split & Relu
input 된 batch * ( p 차원 + a 차원) matrix 를
batch * prediction layer 차원, batch * attention layer 차원 로 쪼갠뒤
- batch * prediction layer 차원 --> Relu의 input
- batch * attention layer 차원 --> 다음 step의 attentive transformer의 input
$\mathrm{f_{1}} ( M[1] \cdot \mathrm{f_{0}})$ = split => $[d[1], a[1]]$
step 2 에서 다시 ⓶ ~ ⓹ 과정이 반복된다.
[ final ] - FC (prediction layer)
각 step 에서 나온 ⓹ output 값을 합한 뒤에 FC 통과
- input : batch * prediction layer 차원
- output : batch * output 차원
( regression 에서의 output 차원 : 1 // classification 에서의 output 차원 : class 개수 )
[ 자세히 살펴보기 ]
# Feature Transformer (⓵ & ⓸)
Mask 과정을 거친 뒤 선택된 feature로 예측값을 잘 맞추기 위해 embedding 하는 단계
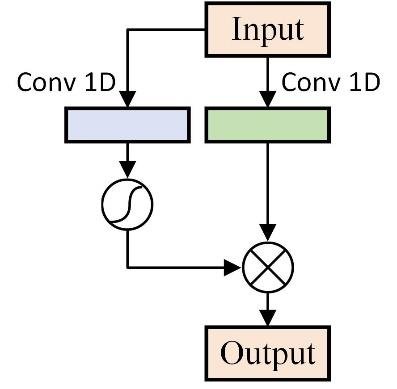

- input : 첫번째 step - batch norm을 거친 input data(=features)
그 이후step - Masking 된 input data(=features)
-output : D차원으로 임베딩된 input data
- Shared across decision steps : 모든 스텝에서 활용되는 block (다음 스텝에 파라미터 공유) - global
- Decision step dependent : 해당 스텝에서 활용되는 block (다음 스텝에 파라미터 공유 x) - local
- Ghost Batch Norm 을 활용 : 기존의 배치사이즈를 nano batch를 분할한뒤 normalization
- GLU 추가 : 2가지 path를 활용 (초록block- 기존 signal이 전달 // 파랑block - sigmoid 변형된 값) → 이 둘을 element wise
신호의 크기를 조정하는 역할을 하게 됨 (LSTM의 Gate 역할)
sigmoid 과정을 hidden tensor size는 반으로 줄어듦
따라서 모든 FC들은 feature transformer는 2배가 되는 hidden tensor를 출력
- residual connection : residual output의 normalization을 위해서 squart(0.5)를 곱함
# split & Relu (⓹)
$\mathrm{f_{1}} ( M[1] \cdot \mathrm{f_{0}})$ = split => $[d[1], a[1]]$
- input : feature transformer의 output
- output : $[d[i]$, $a[i]]$
나뉜 두 tensor의 크기는 $d[i] \in R^{B \times N_{d}} , a[i] \in R^{B \times N_{a}}$
이때 $N_{d}$ 와 $N_{a}$ 의 합은 $N$
- $d[i]$ 는 output을 위해 사용되며 Relu activation의 input이 됨



여기서 나온 dout의 합은 해당 step에서의 feature importance를 의미함
step 마다 나온 모든 dout의 값과 합해서 최종 feature attributes를 계산 할 수 있음
- $a[i]$ 는 마스크 학습을 위해 사용되며 Attentive transformer의 input이 됨
# attentive transformer (⓶) : 학습 가능한 mask 생성


- input : $a[i-1]$ (이전 단계 split output)
- output : D개의 크기를 갖는 sparse matrix $M[i]$ 출력 (이게 Mask 임)
(어떤 feature를 주로 사용할 것인지에 대한 정보 담김, 다음 step에서 활용됨)
- 입력된 $a[i-1]$ 를 FC, BN ($h_{i}$) 과정을 거쳐 D개의 hidden size로 변환 (이때 FC weight matrix 로 학습)
$M[i] = sparsemax(P[i-1] \cdot h_{i}(a[i-1]))$
⓶ -1 FC & Batch norm :
- input 된 $a[i-1]$ 가 FC layer 통과후 Batch normalization → $h_{i}(a[i-1])$
+) FC, BN 에서 나온 weight $h_{i}$
⓶ -2 Prior scale : 이전 단계에서 선택된 변수의 반영률이 점차 낮아지게 하는 term
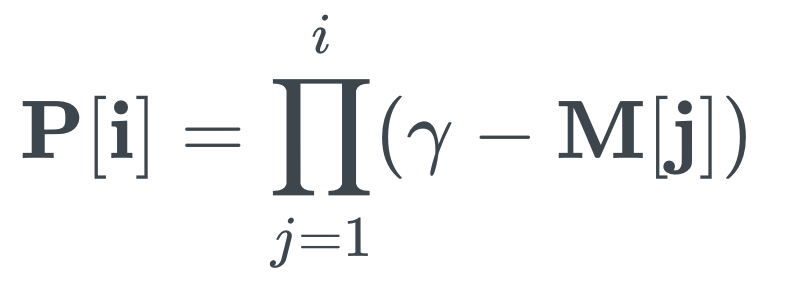
M[j] : 이전 단계 마스크
감마(γ) : 1이상의 값으로 선택하는 하이퍼 파라미터
ex) i=2 (현재 step2), 감마 = [1,1], M[1] = [1,0] (이전단계에서 중요한 칼럼은 첫번째 칼럼) 이라면
p[2] = [1,1] - [1,0] = [0,1]
p[2] = [0,1] (1번째 단계에서 중요한 칼럼이었던 첫번째 칼럼에는 0이 마스킹, 안중요한 칼럼인 두번째 칼럼은 1이 마스킹)
→ 즉, 이전 단계에서 덜 중요한 칼럼에 더 높은 가중치를 부여하도록 함
→ 이전 단계에서 선택된 변수의 반영률이 점차 낮아짐
맨 처음 step에서는 P[0] 의 값이 다 1로 초기화 $1^{B \times D}
⓶ -3 sparse max (activation 함수로 mask를 생성)
$M[i] = sparsemax(P[i-1] \cdot h_{i}(a[i-1]))$
sparsemax는 softmax보다 sparsity를 고려한 활성화함수
softmax 처럼 0과 1사이의 값으로 반환되지만 sparse max 가파름
극단적인 feature selection 효과를 얻음 (선택된 feature의 가중치는 1 가까운 값, 버려진feature의 가중치는 0에 가까운 값)

# Masking (⓷)
- attentive transformer의 output $M_{i}$ 과 이전 step의 feature $f$ 를 곱함 → $M_{i} \cdot f$ masked feature 생성
- attentive transformer의 output은 sparsemax 함수를 거쳤기 때문에
[1, 0] 과 같이 feature 하나를 통으로 버리는 hard feature selection 이 아니라
[0.7, 0.3] 처럼 feature의 중요도를 반영하는 soft feature selection 역할을 한다.
- 이렇게 생성된 masked feature는 다시 feature transformer의 input이 됨
+) Mask 모델 해석 (논문에서 interpretability 부분)
$M_{b,j}[i] = 0$ 인것은 b샘플의 j번째 칼럼이 i 번째 step 에서 어떤 역할도 하지 않았다는 뜻 → feature importance로 해석

Figure 5: Feature importance masks M[i] (that indicate feature selection at ith step) and the aggregate feature importance mask Magg showing the global instance-wise feature selection, on Syn2 and Syn4 (Chen et al. 2018). Brighter colors show a higher value. E.g. for Syn2, only X3-X6 are used.
- 각 스텝에서 활성화된 feature 를 시각화로 확인할 수 있음 (흰색 부분이 모델 학습에 사용 된 것)
- Syn2에서는 feature X3-X6 만 활용 됨
- Magg 는 각 스텝의 feature importance를 결합 했을 때 나오는 결과 시각화
- instance 별 중요도 또한 확인이 가능함 --> explain method로 feature importance와 mask 확인 가능
(자세한 설명은 아래 Question 2 참고)
3.2 Decoding architecture (semi - supervised Learning)
input : Encoded representation (Encoder의 Feature Transformer + split 거친 output)
shape - batch * prediction layer 차원
output : 각 step 의 FC 아웃풋 거친 값의 합
shape - batch * prediction layer 차원 (auto encoder 처럼 output은 input 과 같은 차원)


- encoder에 decoder 구조 결합하면 autoencoder 같은 자기 학습 구조를 가지고 있음
decoder 에서는 아래 우측에서의 (?) 로 된 missing value 를 채워넣는 구조
encoder input 은

이때 마스킹은 Batch * Dimension
--> 채운 뒤 encoder prediction 한다면 더 높은 성능을 기대할 수 있음
4. Experiments
- regression, classification task로 성능 평가
- 데이터 셋의 모든 categorical value 들은 임베딩됨, numerical value들은 전처리 없이 Input
- TabNet은 대부분의 hyperparameter에 대해 그리 예민하지 않음 (abliation study 참고)
4.1 Instance-wise feature selection (synthetic dataset - 임의로 생성한 데이터셋 활용)
global feature selection : 전체 데이터에서 중요한 feature 고르기
instance feature selection : 각 row 별 데이터에서 중요한 feature 고르기
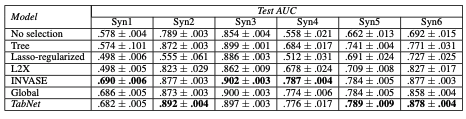
- 6개 임의로 생성된 데이터로 성능을 평가함 --> syn1 ~ syn 6 데이터
(Learning to Explain: An Information-Theoretic Perspective on Model Interpretation 논문에서 가져옴)
- syn 1~3 에서는 각 인스턴스(data row) 별로 중요한 피쳐가 같았음
따라서 syn 1~3 에서는 Tabnet 의 성능이 global feature selection 하는 다른 모델들과 성능이 비슷함
- syn 4~6 에서는 각 인스턴스(data row) 별로 중요한 피쳐가 다름
따라서 불필요한 feature들을 instance wise로 제거해서 성능 향상함
4.2 Performance on real-world datasets
1) Forest cover type dataset : 나무 분류 문제
2) Poker Hand : 카드 분류 문제
3) Sarcos : 로봇 팔 관련 데이터
4) Higgs Boson : 이진 분류 문제
5) Rossman Store Sales : 상점 매출 예측
- instance -wise feature selection 이 날짜 칼럼에서 중요한 역할을 했음
ex) 평일 data (다른 칼럼 중요), 공휴일 data (날짜 칼럼 중요) --> 각 데이터 인스턴스별로 다르게 봄
# Attentive Transformer 의 해석 (Xai)
Figure 5: Feature importance masks M[i] (that indicate feature selection at ith step) and the aggregate feature importance mask Magg showing the global instance-wise feature selection, on Syn2 and Syn4 (Chen et al. 2018). Brighter colors show a higher value. E.g. for Syn2, only X3-X6 are used.
- 각 스텝에서 활성화된 feature 를 시각화로 확인할 수 있음 (흰색 부분이 모델 학습에 사용 된 것)
- Syn2에서는 feature X3-X6 만 활용 됨
- Magg 는 각 스텝의 feature importance를 결합 했을 때 나오는 결과 시각화
- instance 별 중요도 또한 확인이 가능함

============================================================================== ==============================================================================
논문을 읽고 추가로 생긴 의문과 답변 정리
Q1. Tabnet의 mask 학습을 하는가 ? YES
- Tabnet의 mask 또한 학습 파라미터 (weight matrix) 다.
총 2개의 loss 가 업데이트 되는 구조다 (output에 대한 loss, Mask 에 대한 loss)
다른 weight parameter 업데이트를 하듯이, mask 값도 업데이트를 진행
+) self.lambda_sparse는 hyperparameter다. (default 1-e3) - 마스크 loss를 전체 loss에 얼마나 반영시킬지
값이 커질수록 더 sparse 한 mask matrix가 만들어짐
복잡한 데이터 (단순한 feature selection으로 성능을 높이기 어려운 데이터)일 수록 lambda_sparse 낮추길 권장함
loss = self.compute_loss(output, y)
# Add the overall sparsity loss
loss = loss - self.lambda_sparse * M_loss
# Perform backward pass and optimization
loss.backward()
- 여기서 M_loss 는 아래의 수식으로 계산된다. (epsilion은 hyperparameter)

Feature selection으로 선택된 Feature들의 sparsity를 컨트롤하기 위해 entropy term에 반영
Tabnet Encoder의 forward 함수에서는 각 스텝마다의 Mask loss를 구하고 이것의 평균값을 낸 뒤에 다음 epoch 으로 넘어감
Mask가 Dense(not sparse)하면 entropy의 값이 커짐 → Mask가 Sparse 해지도록 (entropy loss 값이 작아지도록) 학습 진행
class TabNetEncoder(torch.nn.Module):
...
def forward(self, x, prior=None):
x = self.initial_bn(x)
if prior is None:
prior = torch.ones(x.shape).to(x.device)
M_loss = 0
att = self.initial_splitter(x)[:, self.n_d :]
steps_output = []
for step in range(self.n_steps):
M = self.att_transformers[step](prior, att)
### 위의 cross entropy 수식 코드로 표현
M_loss += torch.mean(
torch.sum(torch.mul(M, torch.log(M + self.epsilon)), dim=1)
)
# update prior
prior = torch.mul(self.gamma - M, prior)
# output
masked_x = torch.mul(M, x)
out = self.feat_transformers[step](masked_x)
d = ReLU()(out[:, : self.n_d])
steps_output.append(d)
# update attention
att = out[:, self.n_d :]
M_loss /= self.n_steps
return steps_output, M_loss
따라서 마스크의 학습 방향은 총 2개
- 입력된 데이터가 타겟값을 잘 예측할 수 있는 feature 에 더 큰 가중치 부여
- Sparse matrix 가 되도록 entropy term에 의해 학습됨 (feature selection이 제대로 되도록)
→ 마스크가 학습을 하기 때문에, 어떤 데이터 instance가 들어와도 그 값에 최적화된 masking을 진행할 수 있음
Q2. Tabnet에서 각 step 별 마스크와 각 데이터별 feature importance가 확인 가능하다는데 어떻게 볼 수 있나 ?
아래와 같이 학습된 모델에 explain 메소드를 쓰면 추출이 가능하다 .
res_explain은 각 데이터 인스턴스 별 feature importance가 matrix로 뽑히고
res_masks는 각 데이터 스텝별 마스크의 형태가 dictionary 로 뽑힌다.

코드를 뜯어서 보자면....
def explain(self, X, normalize=False):
"""
Return local explanation
Parameters
----------
X : tensor: `torch.Tensor`
Input data
normalize : bool (default False)
Wheter to normalize so that sum of features are equal to 1
Returns
-------
M_explain : matrix // Importance per sample, per columns.
masks : matrix // Sparse matrix showing attention masks used by network.
"""
self.network.eval() ### not update
dataloader = DataLoader(
PredictDataset(X),
batch_size=self.batch_size,
shuffle=False,
)
res_explain = []
for batch_nb, data in enumerate(dataloader):
data = data.to(self.device).float()
M_explain, masks = self.network.forward_masks(data) ### 현재 배치 matrix importance, mask
### mask
for key, value in masks.items():
print(value)
masks[key] = csc_matrix.dot(value.cpu().detach().numpy(), self.reducing_matrix) ## 사이즈 맞추기?
print(masks[key])
### M_explain : matrix importance
original_feat_explain = csc_matrix.dot(M_explain.cpu().detach().numpy(), self.reducing_matrix)
res_explain.append(original_feat_explain)
if batch_nb == 0:
res_masks = masks
else:
for key, value in masks.items():
res_masks[key] = np.vstack([res_masks[key], value]) ### 다음 배치 마스크들 쌓기
res_explain = np.vstack(res_explain) # 전체 배치 importance
if normalize:
res_explain /= np.sum(res_explain, axis=1)[:, None]
return res_explain, res_masks # 전체 배치 importance, 전체 배치 mask
def forward_masks(self, x):
x = self.initial_bn(x)
prior = torch.ones(x.shape).to(x.device) ### prior setting
M_explain = torch.zeros(x.shape).to(x.device) ### Masking - zero initialize
att = self.initial_splitter(x)[:, self.n_d :]
masks = {}
for step in range(self.n_steps): ### step 만큼 돌아
M = self.att_transformers[step](prior, att) ### 1step attentive transformer --> mask 생성
masks[step] = M ### step의 mask dictionary 저장
# update prior - prior scale
prior = torch.mul(self.gamma - M, prior)
# outputƒf
masked_x = torch.mul(M, x) ## Mask * x (element wise)
out = self.feat_transformers[step](masked_x) # masked_x를 이번 step feature transformer 에 input
d = ReLU()(out[:, : self.n_d]) # feature transformer output 에서 n_d(prediction layer 차원)만큼 가져온뒤 relu
# explain
step_importance = torch.sum(d, dim=1) # relu output matrix (n*D) - array 1*D 로 만들기
M_explain += torch.mul(M, step_importance.unsqueeze(dim=1)) # Mask * relu array
# update attention
att = out[:, self.n_d :]
return M_explain, masks* foward_mask 함수
- input : prediction 하는 test data (batch size 만큼 분할 된 것)
- output : M_explain, res_masks
M_explain : input X에 대해 각 스텝별 Relu output*mask 곱한 값을 합한 것 (아래 이미지 feature atrributes)
input X에서 학습에 중요한 feature에는 큰 값이 부여됨 ==> 따라서 feature importance로 해석

masks : 각 스텝별 사용된 마스크 (딕셔너리 형태로 저장)
{step0: [0,0,0,1,0,0], step1: [0,0,1,0,0,0] ...}
* explain 함수
- input : prediction 하는 test data
- output : res_explain, res_mask
res_explain : M_explain matrix(batch_size * feature 수)를 concat --> shape : test data 개수 * feature 수
res_masks : masks (dictionary)
Key : step0, step1, step2...
value : array (해당 스텝의 데이터별 마스크 형태) --> shape : test data 개수 * feature 수
각 데이터의 step 별 마스크의 변화를 보고 싶다면, res_masks 시각화
각 데이터의 전체 step importance를 확인하고 싶다면, res_explain 시각화
참고 link : https://housekdk.gitbook.io/ml/ml/tabular/tabnet-overview
TabNet Overview - noviceforever
좀 더 자세히 기술하자면, Feature transformer 블록에서 임베딩(embedding)을 수행하고, Attentive transformer 블록에서 trainable Mask를 생성합니다. 이 Mask는 3가지 용도로 활용됩니다. 1) Feature Importance를 계산,
housekdk.gitbook.io