[Deep Learning] RNN, LSTM, GRU 차이점 (순환 신경망 모델들)
Q. RNN, LSTM, GRU 각각의 차이는 뭔가요 ?
각 모델들이 서로의 어떤 점을 보완하면서 등장했는지 이해하면 쉽다. 먼저 RNN부터
1. RNN - recurrent neural network


1) 핵심 개념
입력 갯수 출력 갯수에 따라서 one to many, many to one, many to many 로 나눠지지만
핵심은 이전 hidden state 의 아웃풋과 현시점의 인풋이 함께 연산 된다는 것
2) 문제 입력 시퀀스의 길이가 너무 길면 (Long sequence)
--> 그레디언트 주는 편미분 과정에서 (Back Propagation Through Time)
그레디언트가 사라지거나 폭발하는 문제가 생김 (Gradient Vanishing , Gradient Exploding)

결국 다른 딥러닝 모델들과 마찬가지로 Back propagation 과정을 통해 Gradient 를 편미분하는데,
문제는 RNN 의 구조상 입력 데이터의 길이가 길어지면 에러 값 계산 후
처음 hidden state 까지 back propagation 하며 gradient 주는 과정이 너무 길기 때문에,,
gradient 값이 연산 과정에서 아주 작아져 버림 결국 gradient가 전달이 잘 안된다는것 ==> 이를 Gradient Vanishing 이라 한다.
*** 정말 쉽게 비유하자면, 내가 시험 문제를 겁나게 풀고있는데, 마지막에 채점을 해
하지만 그 문제가 너무 예전에 푼 문제라 채점을 해도 기억이 안나는 그런 느낌.
학습이 안되는 상황..

하지만 문제점은 many to many 와 같은 구조에서 초반부에 입력된 것이 후반부에 잊혀지는 것이다. (마치 사람같구나)
이러한 문제를 Gradient vanishing 이라 한다. 학습에 영향을 미치는 gradient 가 점점 소멸되는 것

따라서 예전 기억도 계속 리마인드 시켜주는 학습 방법이 필요해짐 !!!! 그것ㅇl LSTM !
2. LSTM
따라서 우측처럼 계속 기억을 유지시켜 줄 수 있게 하는 LSTM 이 등장했다.
LSTM의 구조는 아래와 같고,
특징은 2개의 벡터 ( 단기 상태 ht / 장기 상태 Ct ) 3개의 게이트 ( input gate, output gate 그리고 forget gate )
를 가지고 있다는 점이다


LSTM 셀에서는 상태(state)가 두 개의 벡터 와 로 나누어 진다는 것을 알 수 있다.
ht 를 단기 상태(short-term state), Ct를 장기 상태(long-term state)라고 볼 수 있다.각 게이트를 정말 간단하게만 정리하자면 컨셉은 이렇다
input gate : 이번 입력을 얼마나 반영할지
output gate : 이번 정보를 얼마나 내보낼지
forget gate : 과거 정보를 얼마나 까먹을지
그리고 이 모든 장기기억이 ct에 담김으로써 RNN의 문제를 해결함
3. GRU
위의 복잡한 구조를 간단히 시킨게 GRU
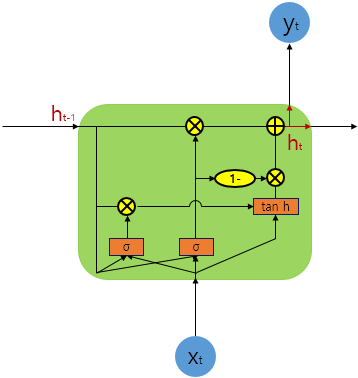
차이점 !
- GRU는 게이트가 2개, LSTM은 3개
- GRU는 내부 메모리 값 ( ct )이 외부에서 보게되는 hidden state 값과 다르지 않음. LSTM에 있는 출력 게이트가 없음 !
- 입력 게이트와 까먹음 게이트가 업데이트 게이트 z로 합쳐졌고, 리셋 게이트 r은 이전 hidden state 값에 바로 적용
- 따라서, LSTM의 까먹음 게이트의 역할이 r과 z 둘 다에 나눠졌다고 생각할 수 있음
- 출력값을 계산할 때 추가적인 비선형 함수를 적용하지 않음
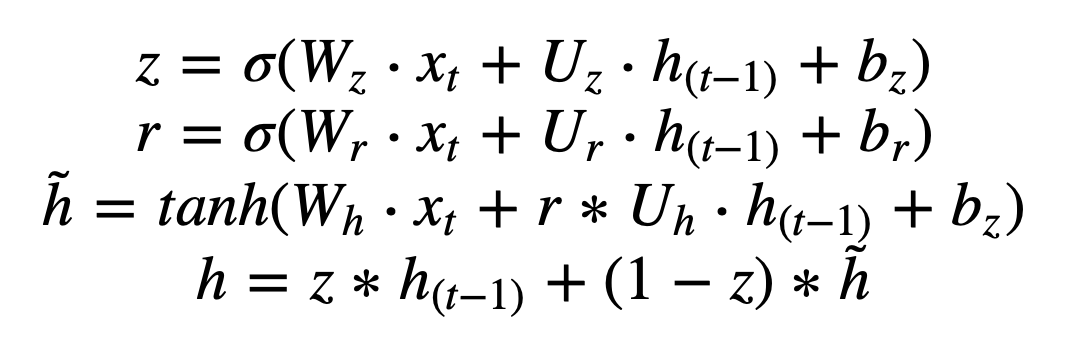
1) Rt : reset gate (지난 정보를 얼마나 버릴지)
현재 시점의 입력값 (xt)가 입력되면 그 시점의 가중치 Wr 와 내적
전 시점의 hiddenstate ht-1는 그시점의 가중치 Ur 와 내적
마지막으로 두 계산이 더해져 sigmoid 함수에 입력 --> 결과는 0~1사이값
2) Zt : update gate (이번 정보를 얼마나 반영할지)
현재 시점의 입력값 (xt)가 입력되면 그 시점의 가중치 Wz 와 내적
전 시점의 hiddenstate ht-1는 그시점의 가중치 Uz 와 내적
마지막으로 두 계산이 더해져 sigmoid 함수에 입력 --> 결과는 0~1사이값
3) ~h : 현재 시점에 과거의 메모리를 얼마나 사용할거냐
현재 시점의 입력값 (xt)가 입력되면 그 시점의 가중치 Wh 와 내적
전 시점의 hiddenstate ht-1는 그시점의 가중치 Uh 와 내적하고 Rt(지난 정보 버림값)와 성분 곱
마지막으로 두 계산이 더해져 tanh 함수에 입력
--> 결국 Rt, Zt 각각 현시점 인풋 Xt와 이전시점 hidden state ht-1 을 weight와 곱한뒤 sigmoid 통과 시키는 구조
다른 점은 연산되는 weight matrix 값이 다르다는 것.
4) h : 최종 메모리 정보
update gate 출력값 Zt (이전정보 얼마나 반영) 와 이전시점 hidden state ht-1를 성분 곱
update gate 에서 버리는 값인 1-Zt (이전정보 얼마나 안반영) 와 현재시점 hidden state ht 을 성분 곱
참고 link :
데이터과학 유망주의 매일 글쓰기 — 열 일곱 번째 토요일
GRU(Gated Recurrent Unit)
conanmoon.medium.com
aikorea.org/blog/rnn-tutorial-4/
RNN Tutorial Part 4 - GRU/LSTM RNN 구조를 Python과 Theano를 이용하여 구현하기
WildML의 네 번째 (마지막!) RNN 튜토리얼입니다. 마지막 포스트에서는 최근에 가장 널리 쓰이는 RNN의 변형 구조인 LSTM과 GRU의 구조와 구현에 대해 다룰 예정입니다. 이전 번역 포스트들과 마찬가지
aikorea.org
위키독스
온라인 책을 제작 공유하는 플랫폼 서비스
wikidocs.net
ratsgo.github.io/natural%20language%20processing/2017/03/09/rnnlstm/
RNN과 LSTM을 이해해보자! · ratsgo's blog
이번 포스팅에서는 Recurrent Neural Networks(RNN)과 RNN의 일종인 Long Short-Term Memory models(LSTM)에 대해 알아보도록 하겠습니다. 우선 두 알고리즘의 개요를 간략히 언급한 뒤 foward, backward compute pass를 천천
ratsgo.github.io